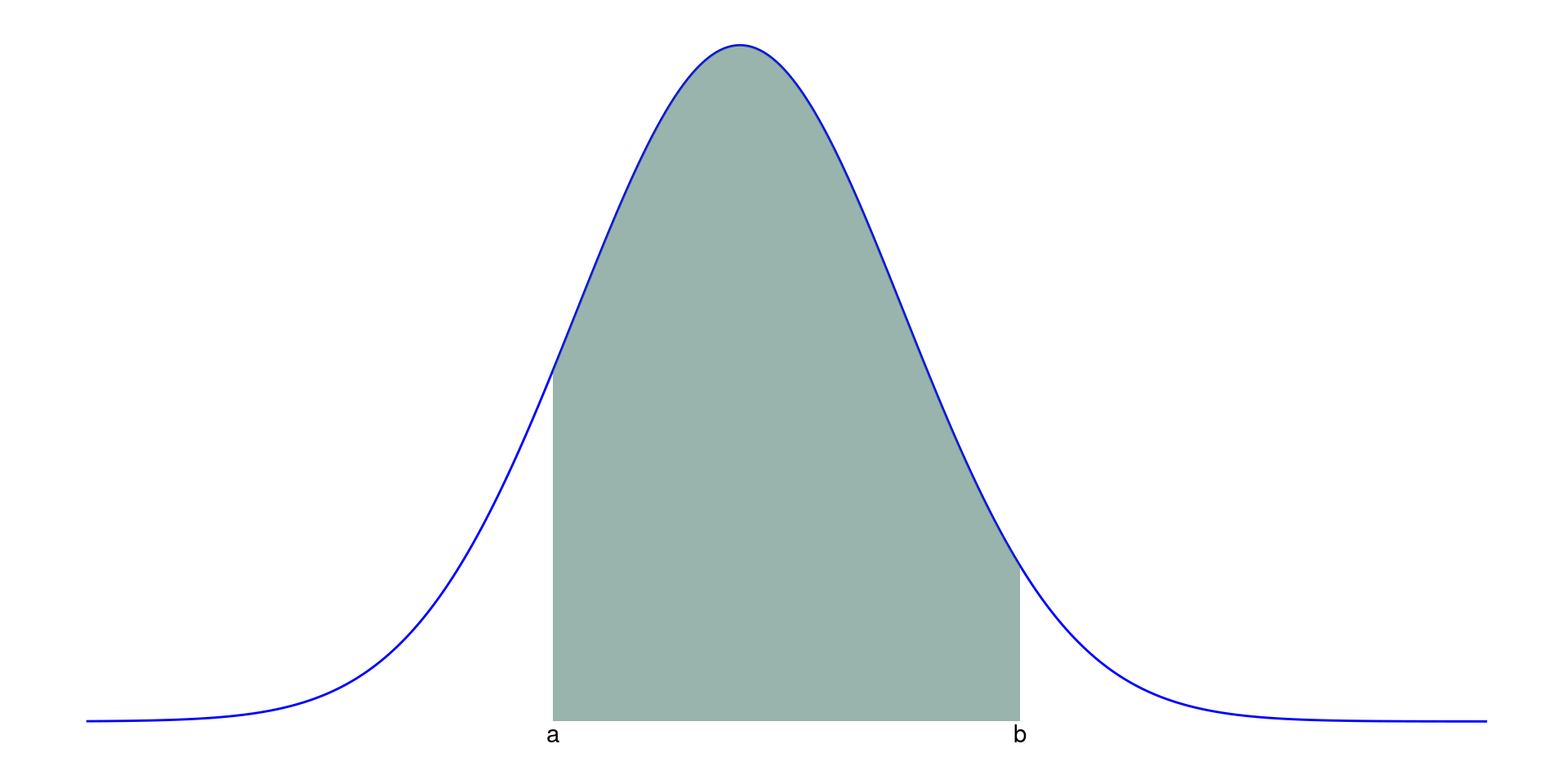
The Normal Distribution!
STAT 120
Normal Distribution
A normal distribution has a symmetric bell-shaped density curve.
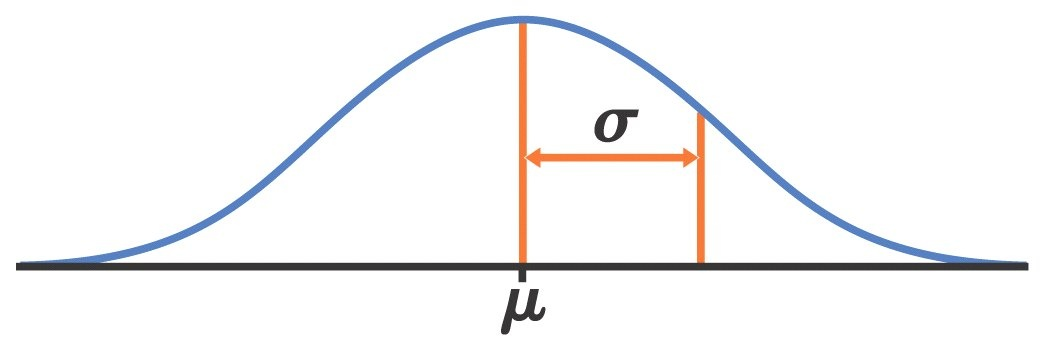
The Normal Model: \(X \sim N(\mu, \sigma)\)
The mean and SD determine how a normal density curve looks. The normal model parameters are
- \(\mu\) = model mean (center)
- \(\sigma=\) model SD (variability)
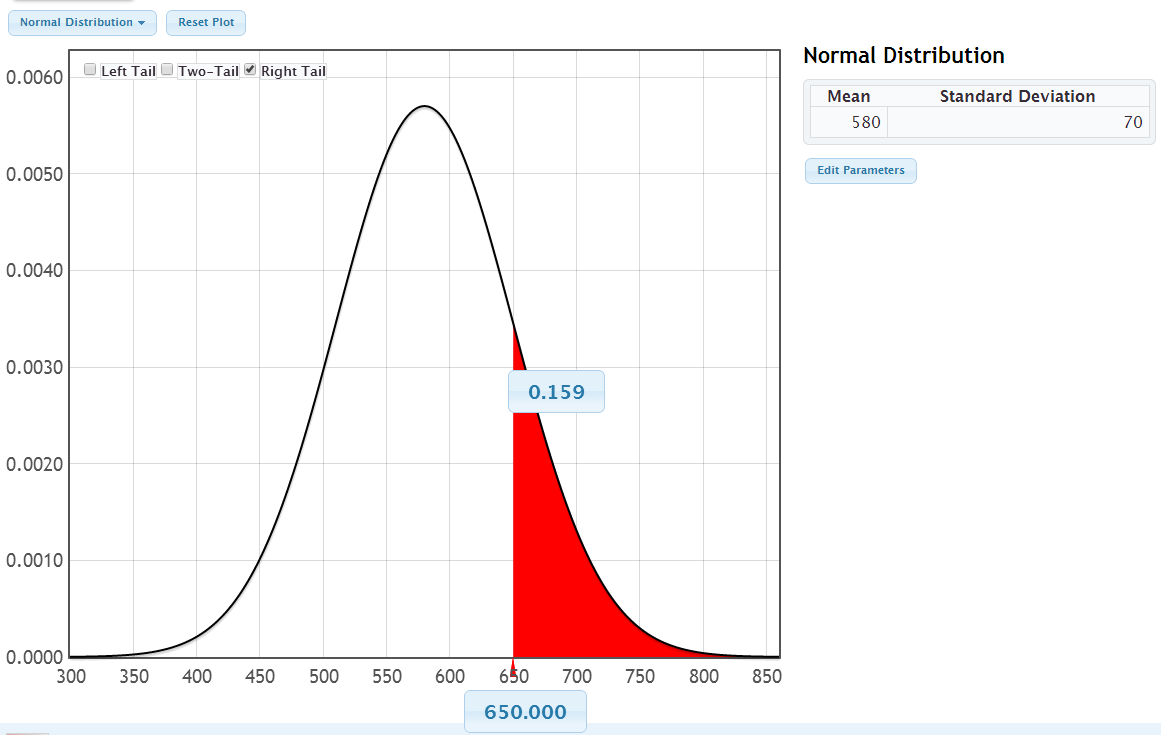
Verbal SAT \(\sim N(580,70)\)
What proportion of people score above 650?
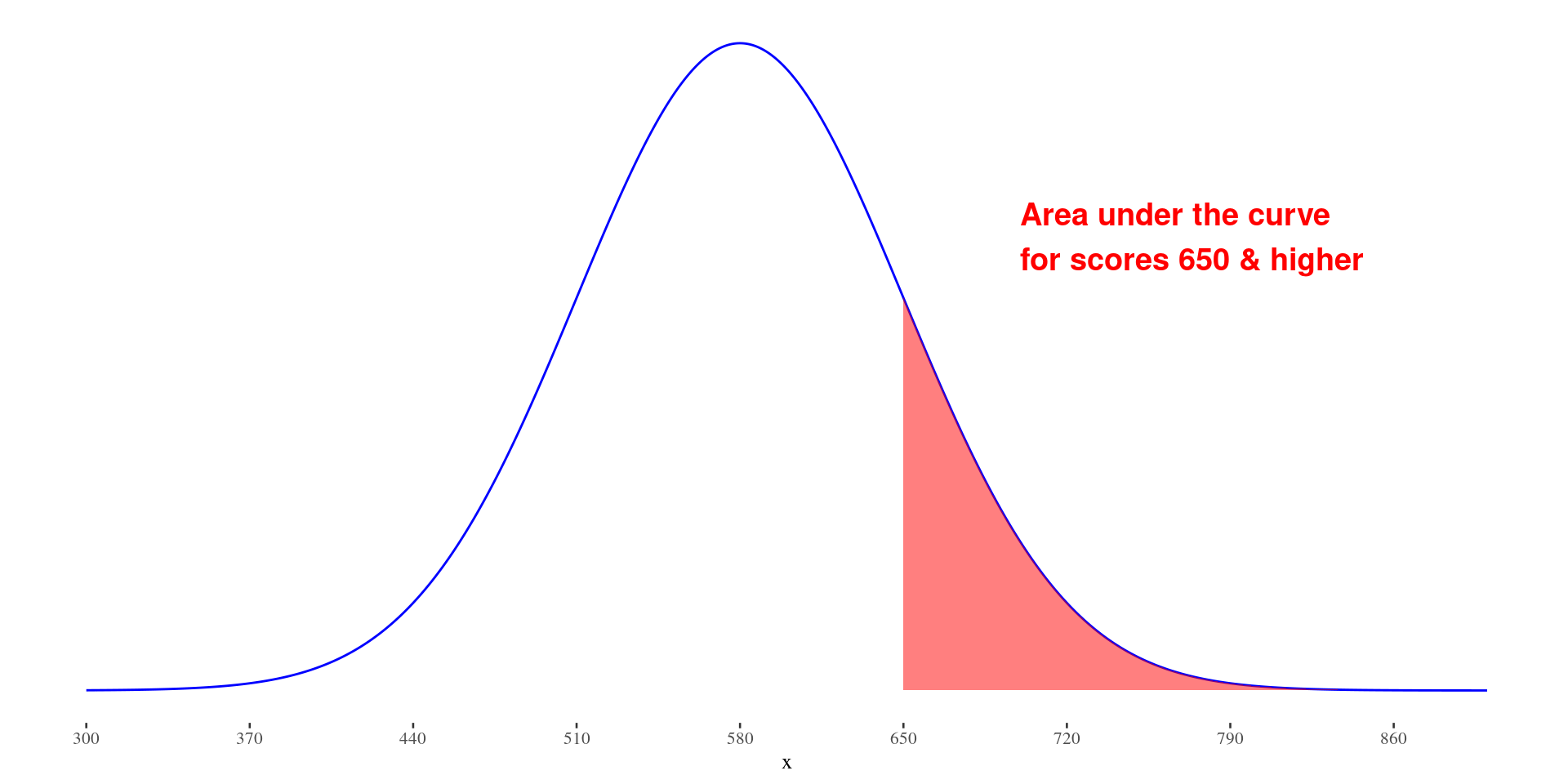
StatKey – Verbal SAT: What proportion of people score above 650?
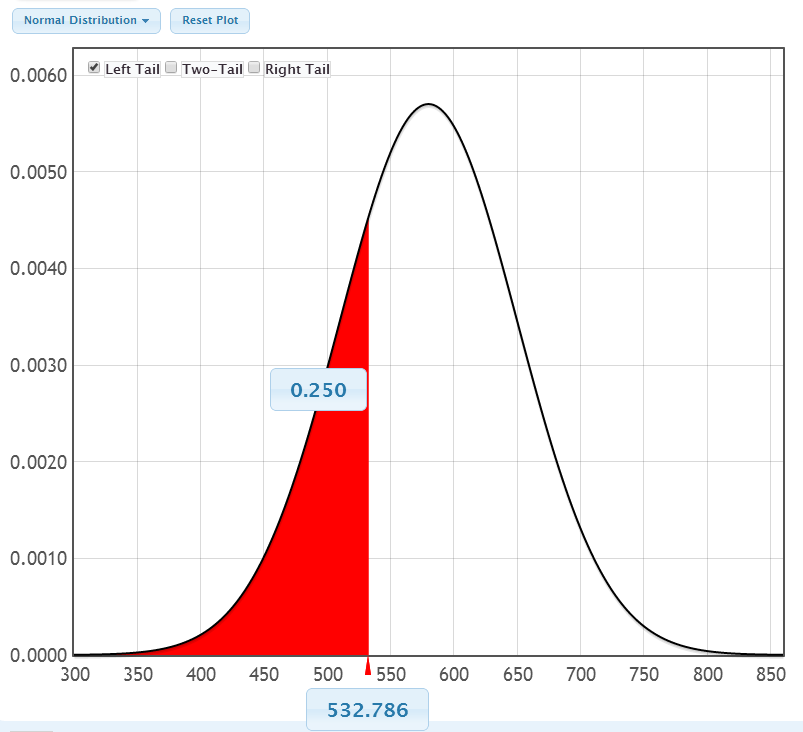
StatKey – Some observations 1
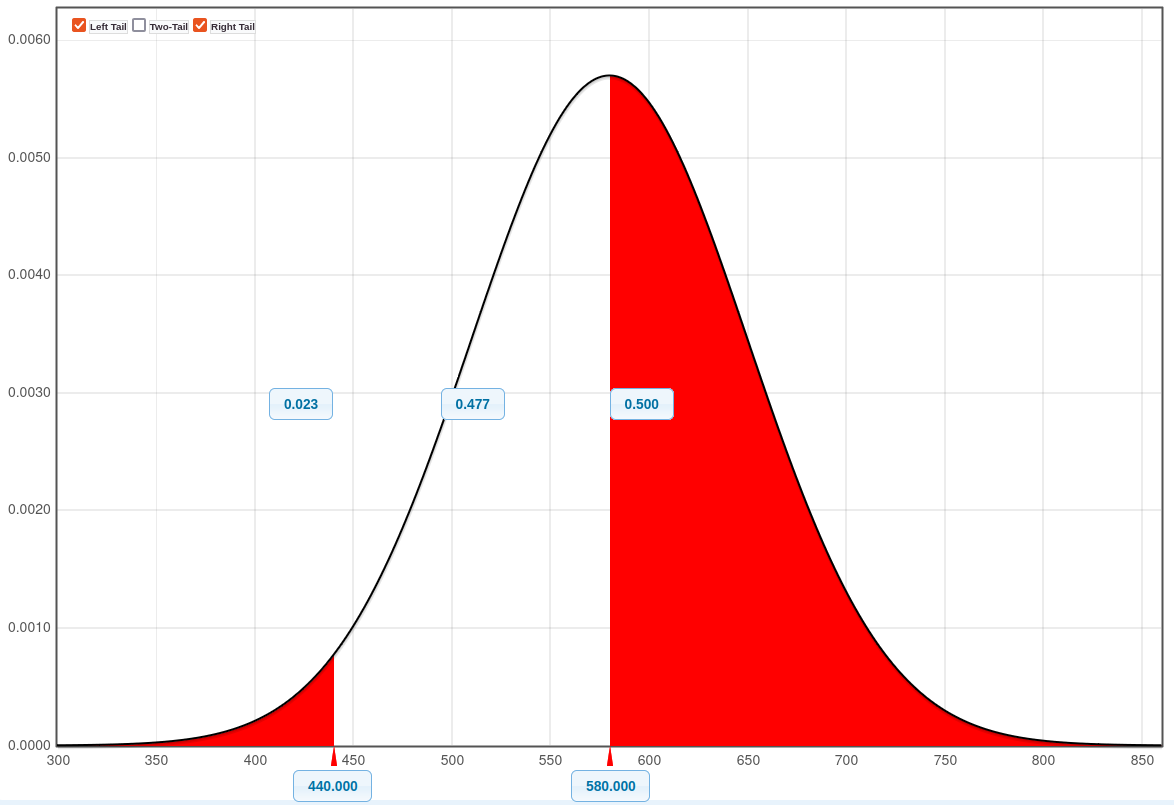
StatKey – Some observations 2
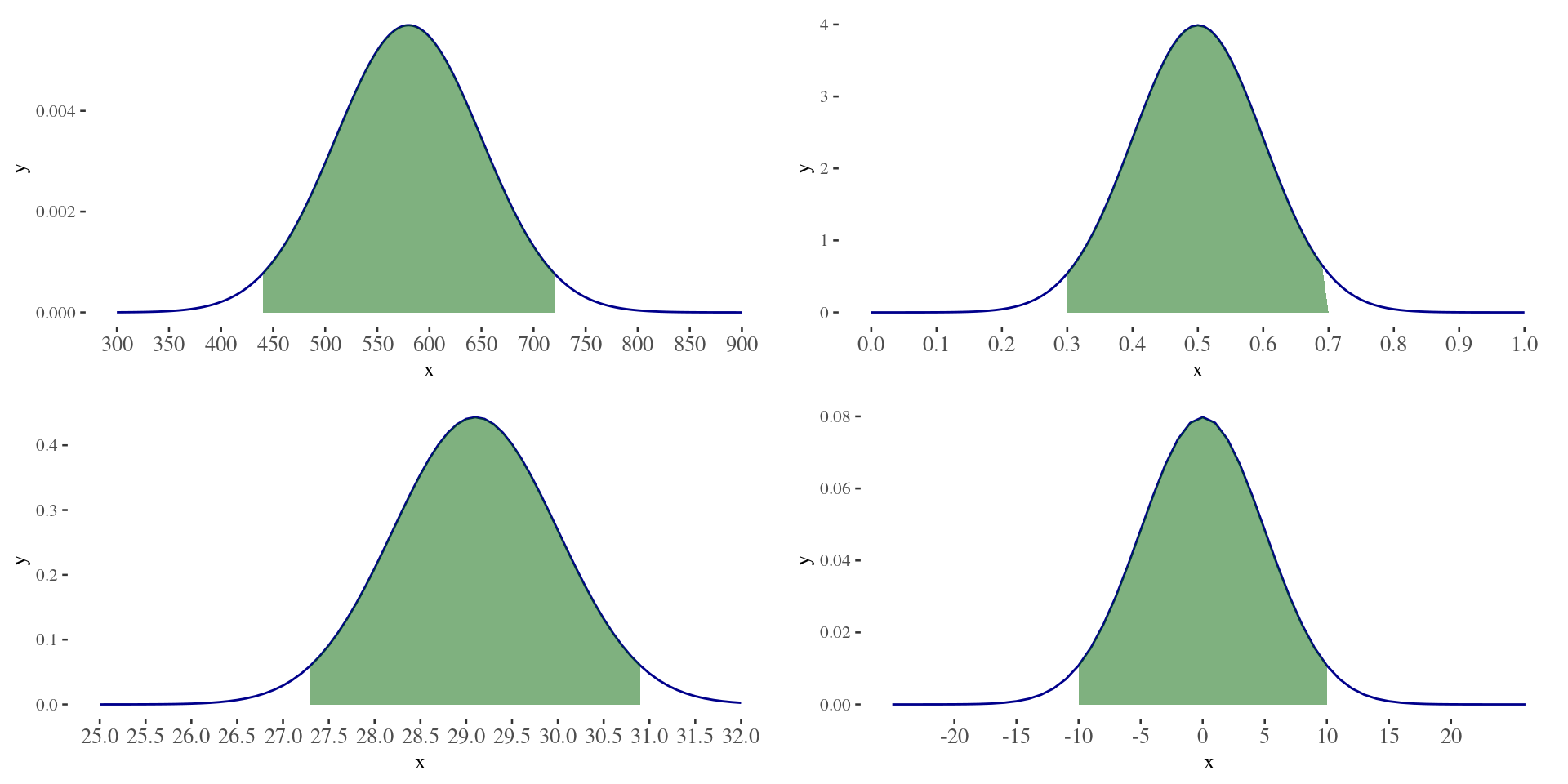
What is common in all 4 figures?
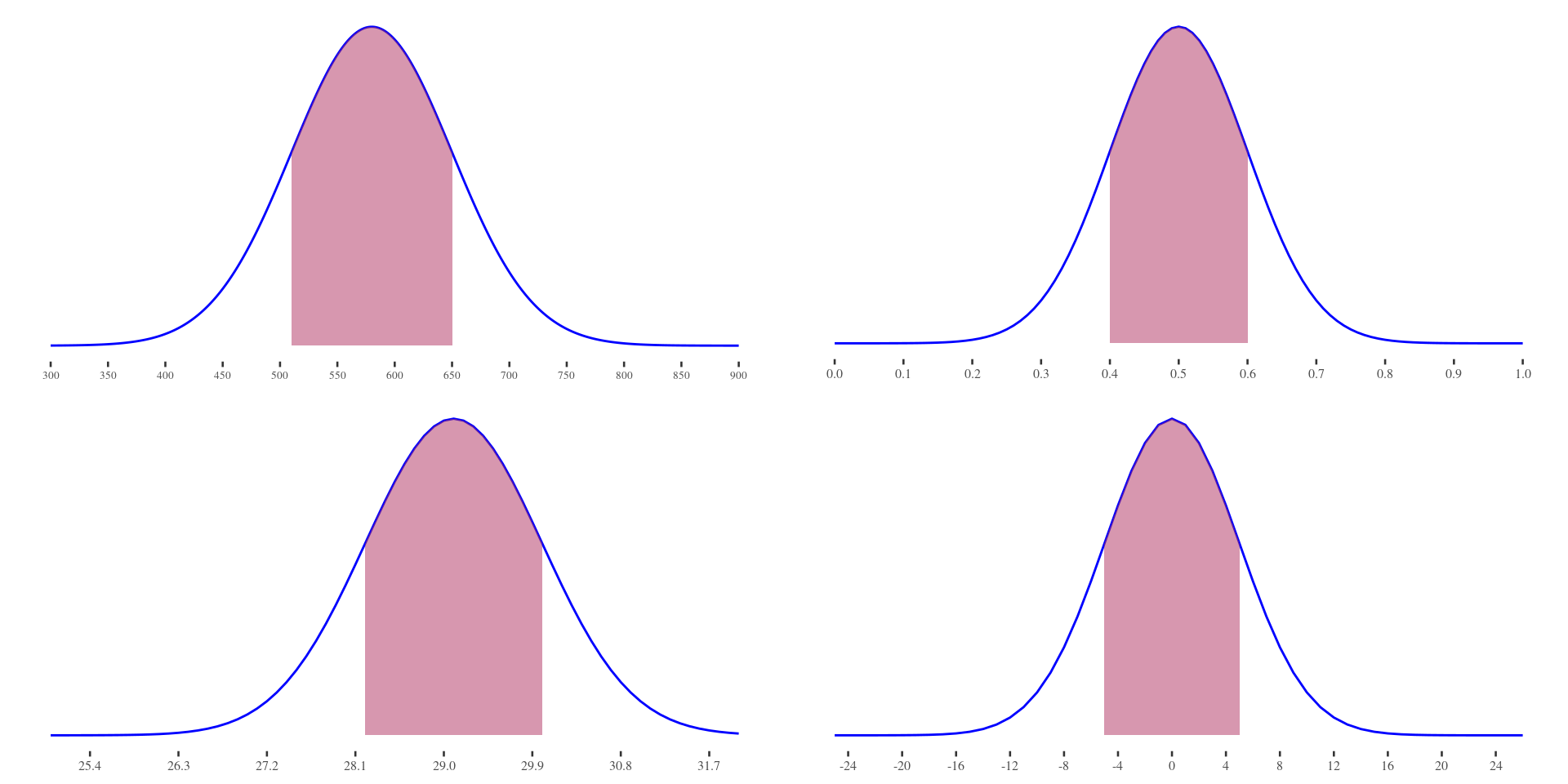
What is common in all these 4 figures?
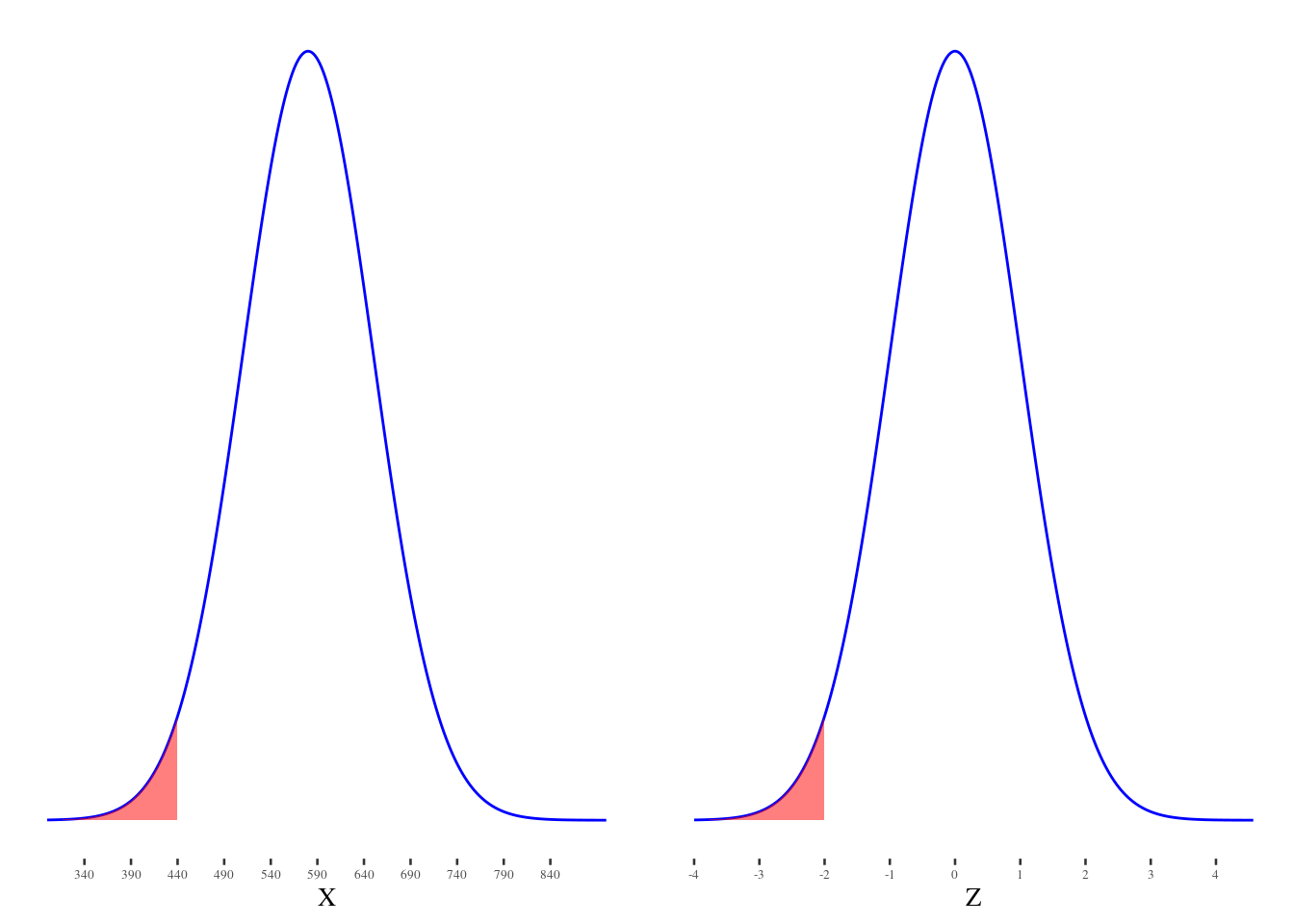
Connecting any Normal model to the standard normal model
Area below x = Area below z
Group Activity 1

- Please download the Class-Activity-15 template from moodle and go to class helper web page
30:00