Two Quantitative Variables: Association
STAT 120
Example: Associations in Car dataset
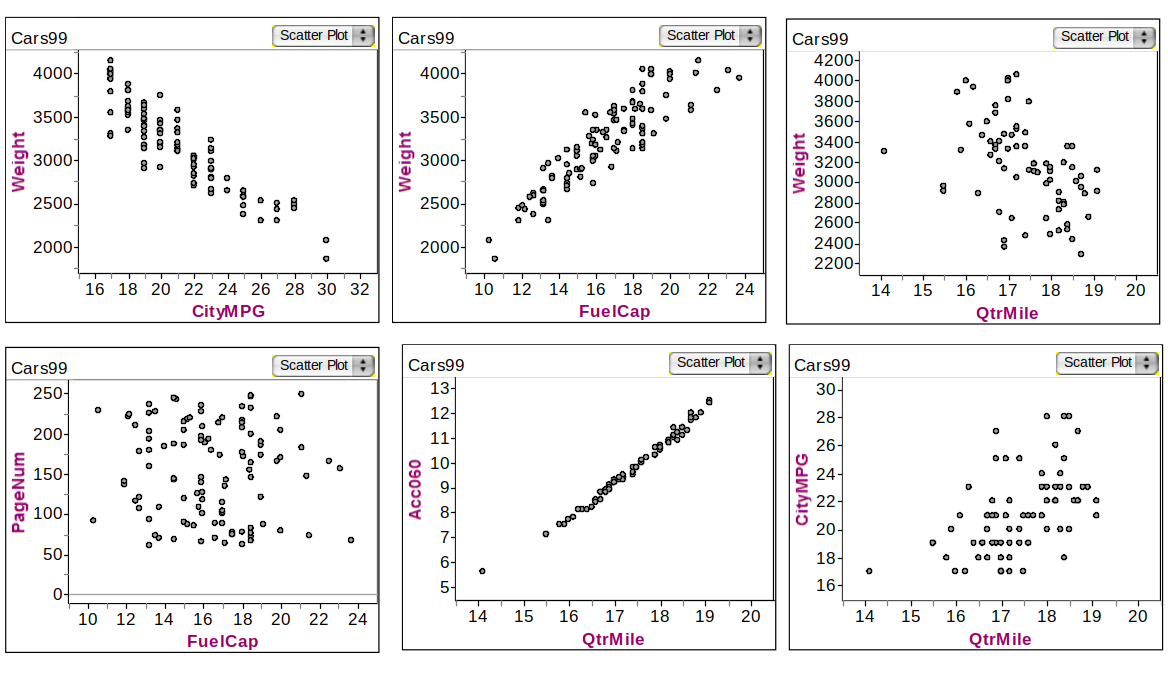
Various Associations of quantitative variables in Cars data
Car Correlations
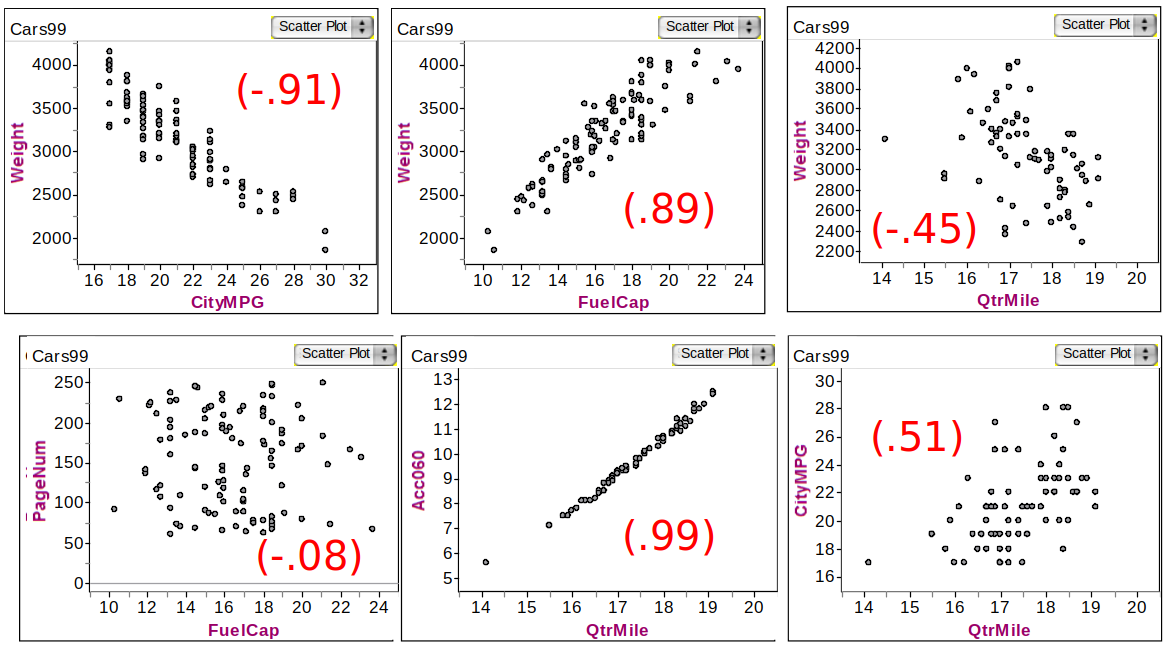
Correlations of various variables in Cars data
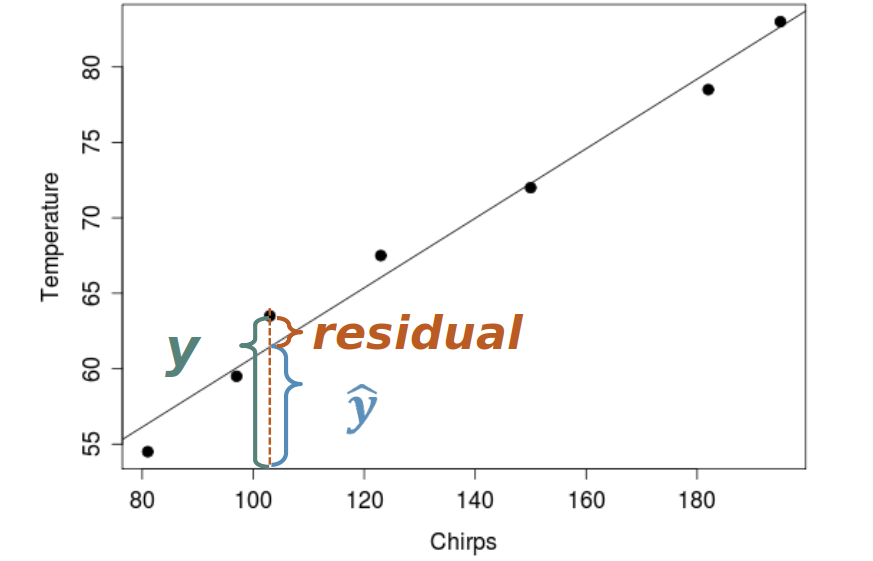
Residuals
Geometrically, residual is the vertical distance from each point to the line
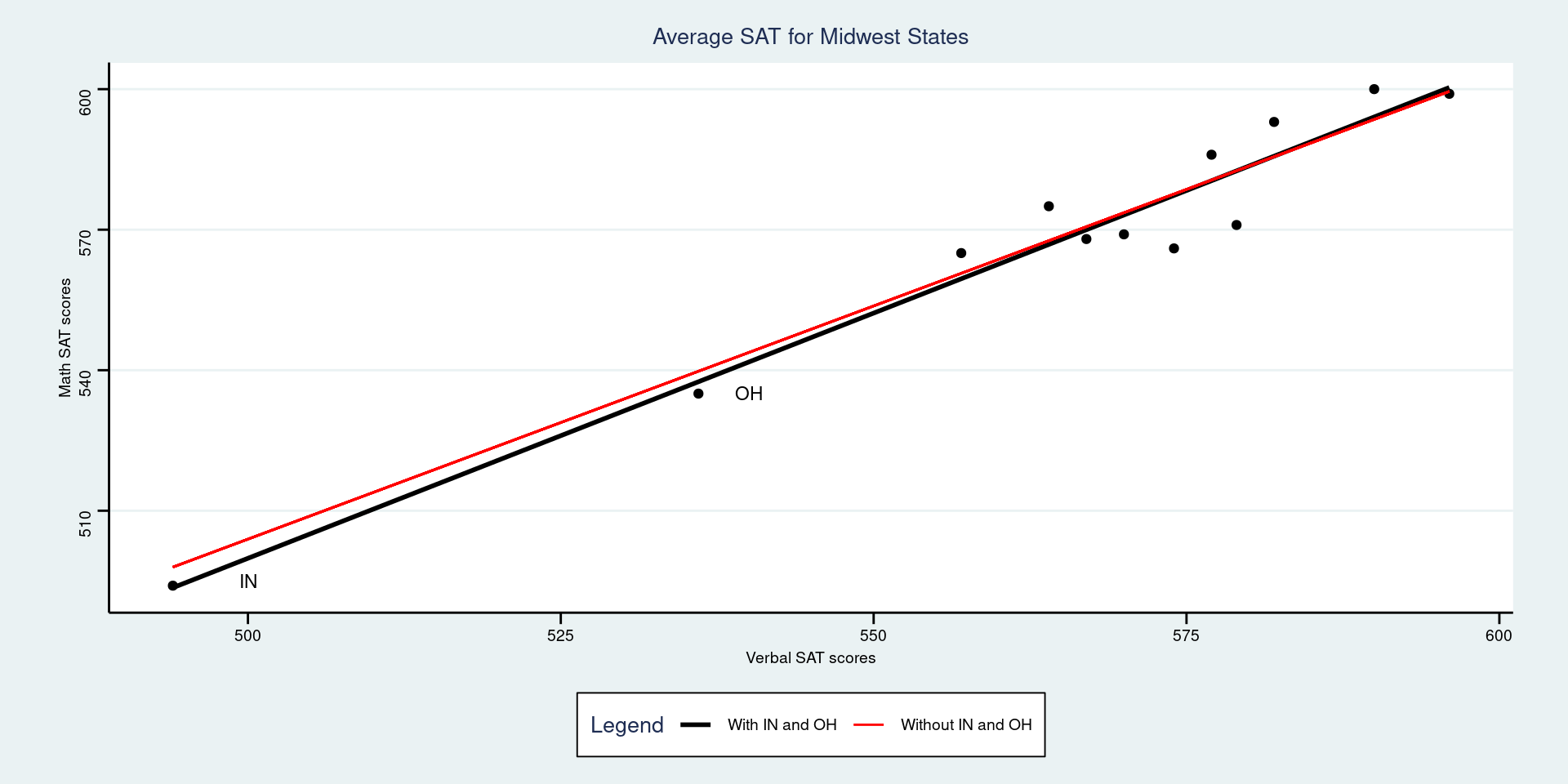
Presence of Outliers
Outliers can be very influential on the regression line. Remove the points and see if the regression line changes significantly
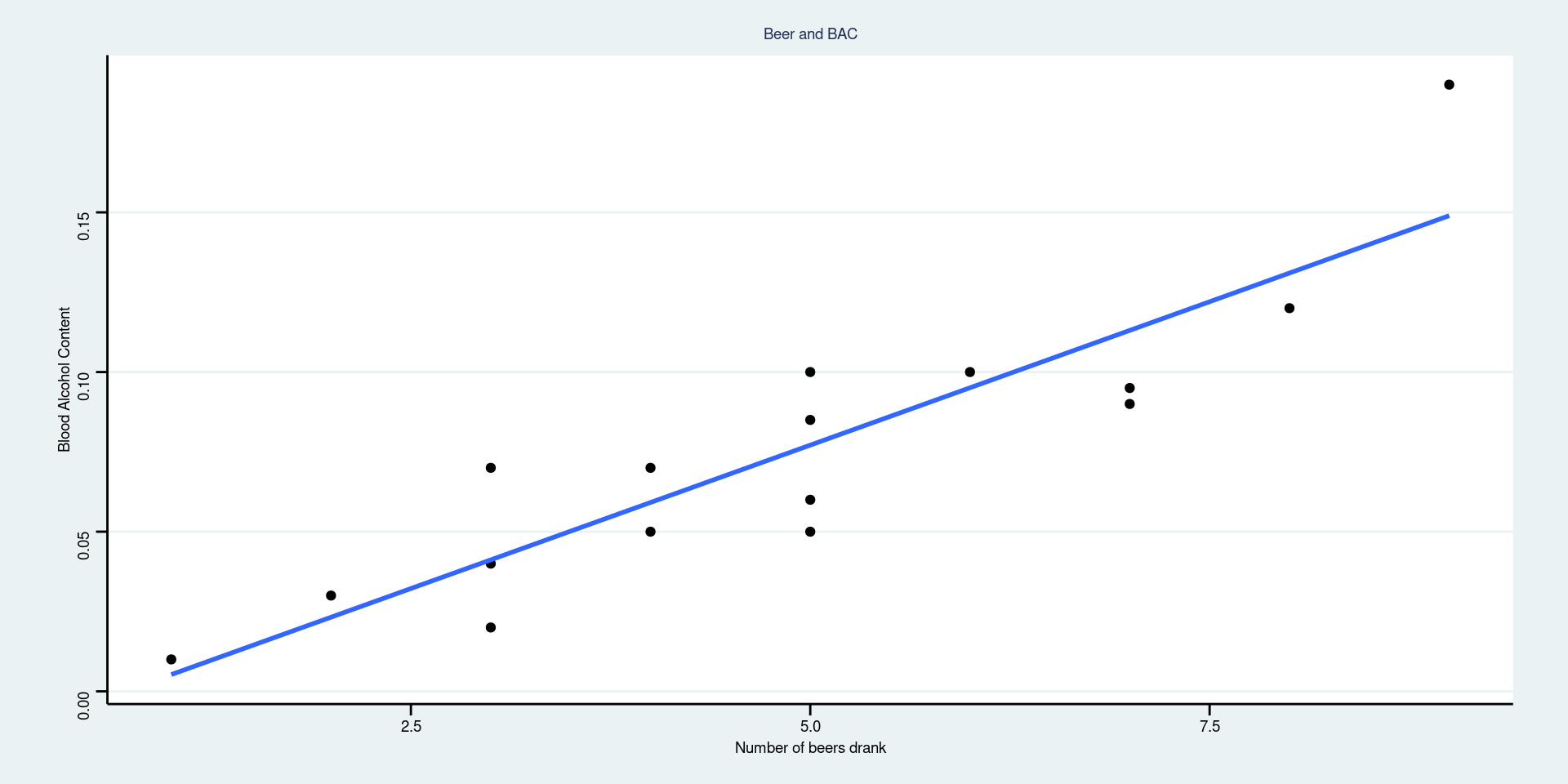
Regressing BAC on number of beers
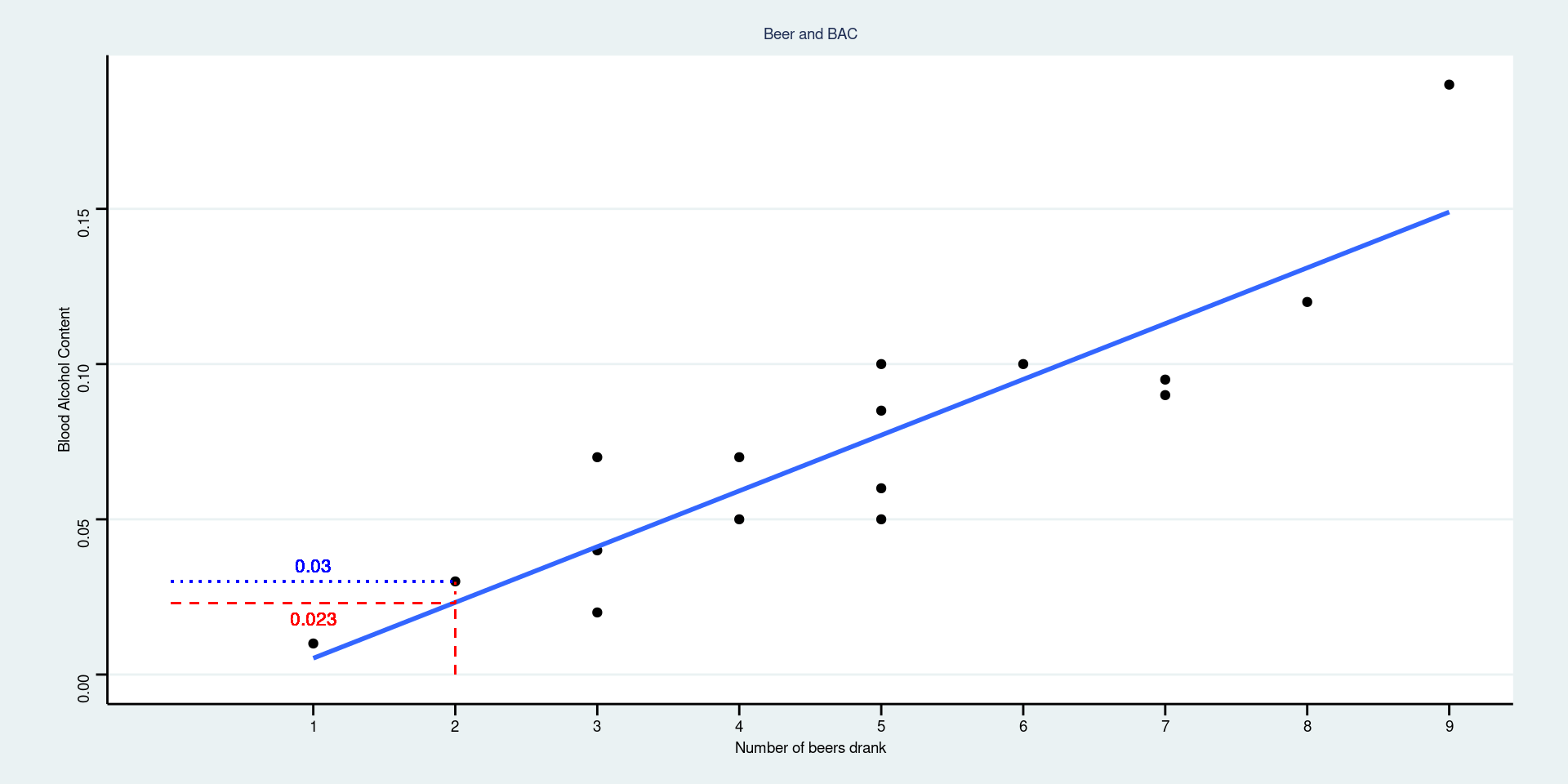
If your friend drank 2 beers, what is your best guess at their BAC after 30 minutes? \[\widehat{BAC} = -0.0127 + 0.0180(2) = 0.023\]
Regressing BAC on number of beers
Find the residual for the student in the dataset who drank 2 beers and had a BAC of 0.03. The residual is about \(y - \hat{y} = 0.03 - 0.023 = 0.007\)
Adding a categorical variable (confounding variable)
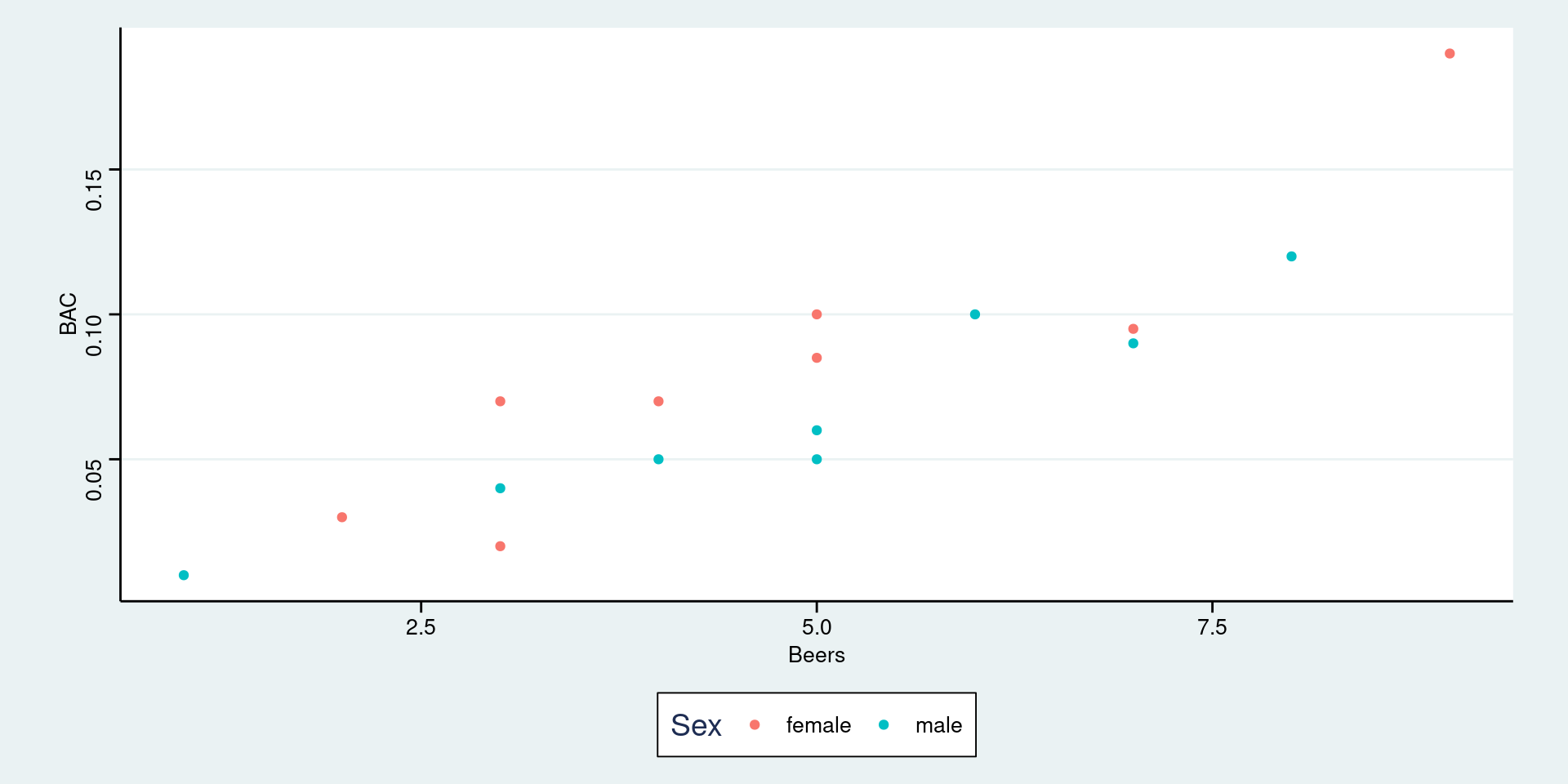
Visually split the data by Sex. Potentially find different trends.
Adding a categorical variable (confounding variable)
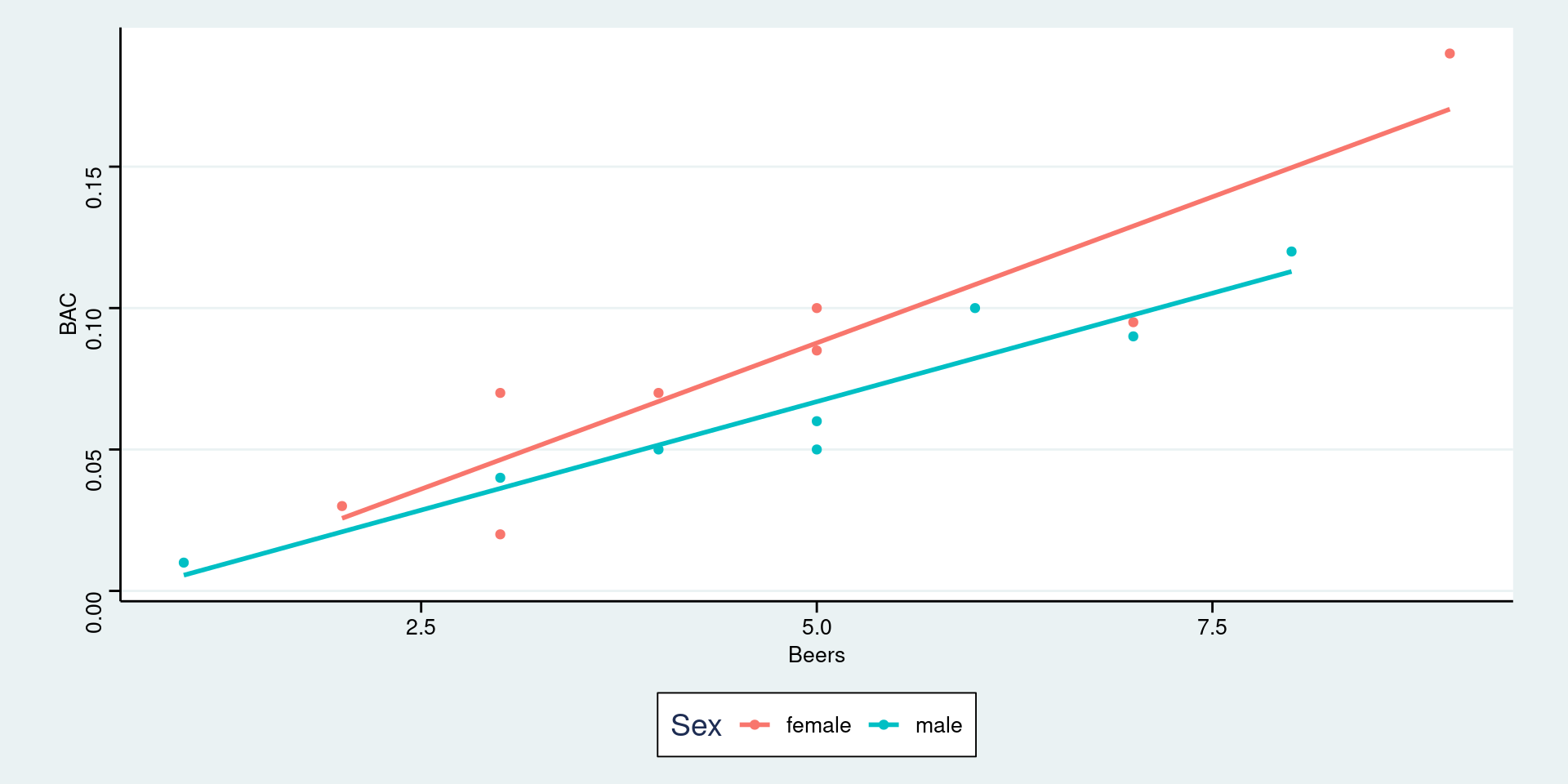
Visually infer difference in Sex in terms of correlation or intercepts
Group Activity 1

- Please download the Class-Activity-6 template from moodle and go to class helper web page
20:00