Problem 1: Comparing % religious guess by religion
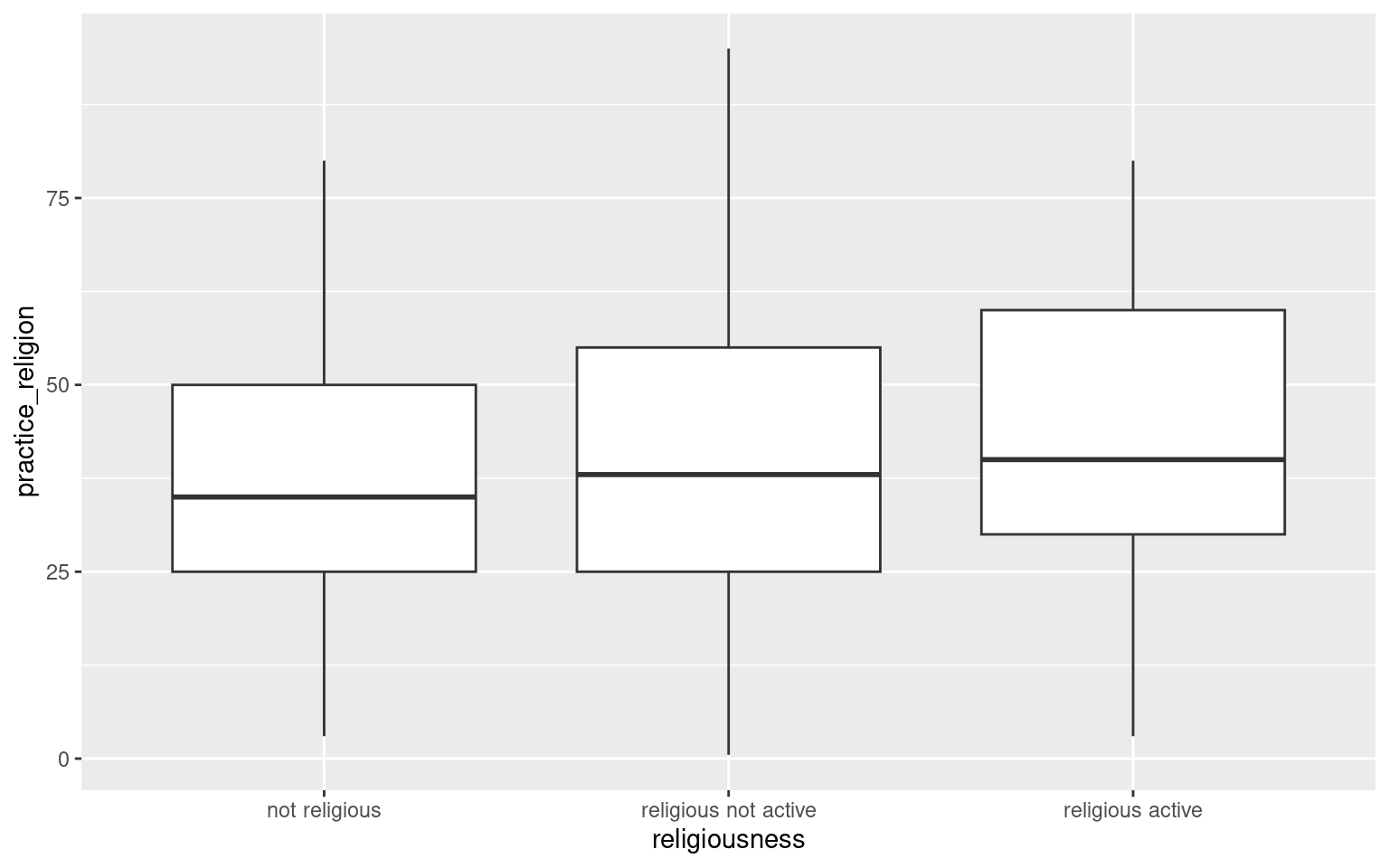
One of the class survey questions asked respondents to give their best guess at the percentage of students at Carleton who practice a religion. Here we can compare responses to this question by the religiousness of the respondent:
library(dplyr)library(ggplot2)# read the data survey <-read.csv("https://raw.githubusercontent.com/deepbas/statdatasets/main/Survey.csv") # and drop the rows containing missing values using the tidyr packagesurvey <- survey %>% tidyr::drop_na()# make a new variable called `practice_religion_percentage` (more informative variable name)survey <- survey %>%mutate(practice_religion = Question.7)# rename comfort level using fct_recode() from the forcats packagesurvey <- survey %>%mutate(religiousness = forcats::fct_recode(Question.8, `not religious`="not religious",`religious not active`="religious but not actively practicing",`religious active`="religious and actively practicing my religion"),religiousness = forcats::fct_relevel(religiousness,"not religious","religious not active","religious active"))ggplot(data = survey, aes(x = religiousness, y = practice_religion)) +geom_boxplot()
We want to determine if the differences in observed mean guesses are statistically significant. State the hypotheses for this test.
Click for answer
Answer: Let \(\mu\) be the true mean religous % guess in a given religiousness group. Then \(H_0: \mu_{notRelig} = \mu_{Relig,Act} = \mu_{Relig,NotAct}\) vs. \(H_A:\) at least one mean is different.
(b) Check assumptions
Can use trust the results from a one-way ANOVA test?
Answer: Yes, the assumptions are met. The distributions within each group are slightly skewed or roughly symmetric, and the sample sizes within each group are all at least 30. In addition, the SD in each group are close to each other (18% to 19.2%).
(c) One-way ANOVA test
Assuming part (b) checks out, run the one-way ANOVA test to compare means:
guess.aov <-aov(practice_religion ~ religiousness, data = survey)summary(guess.aov)
Df Sum Sq Mean Sq F value Pr(>F)
religiousness 2 607 303.6 0.898 0.408
Residuals 347 117321 338.1
What is the F test stat value?
Click for answer
Answer:\(F = 0.898\)
Interpret the p-value.
Click for answer
Answer: If there is no difference in true mean guess in all three groups, we would see an F test stat of at least 0.898 about 40.8% of the time.
What is your conclusion?
Click for answer
Answer: The differences in mean guesses that we’ve observed in our sample are not statistically significant. We don’t have evidence that the true mean guesses for the three religiousness groups are different.
(d) Describe the association?
If you found a statistically significant difference in means in part (c), describe how the groups differ. If you did not find a statistically significant difference in part (c), estimate the average guess for all students in the (hypothetical) population of 215 students.
Click for answer
Answer: We didn’t find a statistically significant difference in part (c). So what is our best estimate of the average guess for all students, since responses don’t seem to differ by religiousness?
t.test(survey$practice_religion)
One Sample t-test
data: survey$practice_religion
t = 39.882, df = 349, p-value < 2.2e-16
alternative hypothesis: true mean is not equal to 0
95 percent confidence interval:
37.25428 41.11927
sample estimates:
mean of x
39.18677
We are 95% confident that the mean guess at the percentage of religious students at Carleton is between 37.3% to 41.1% for all math 215 students.
not religious religious not active religious active
38.05155 40.18556 41.31579
What if there was a difference?!
Use EDA to describe how the sample means differ. Does it look like all three means are different, or does one mean look different from the rest? The sample mean responses from the two religious groups look similar (active: 41.3%; not active: 40.2%) but the mean response of the not religious group is lower (38.1%).
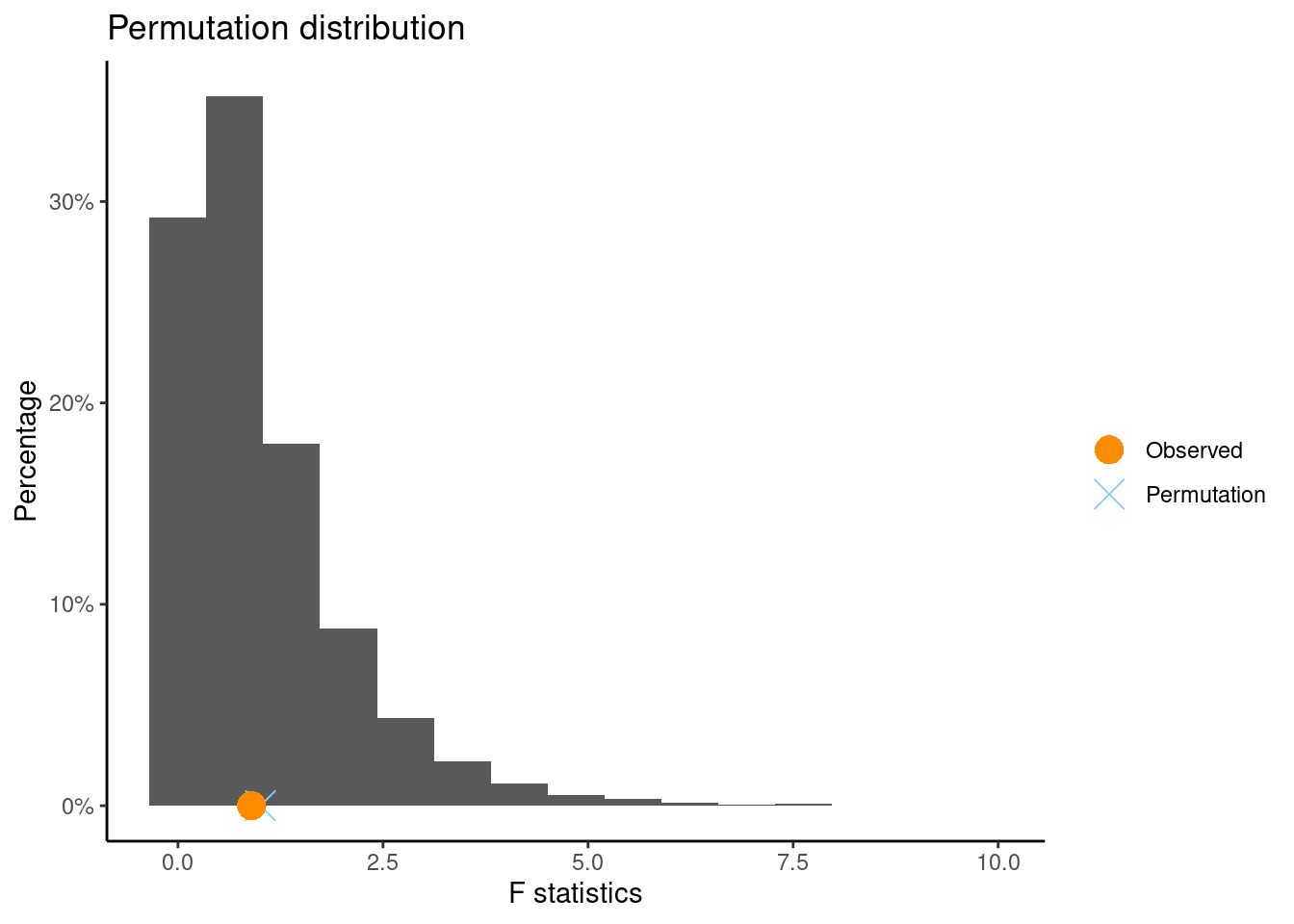
The conditions for using the theoretical ANOVA are met in this example. However, if we were to use a randomization approach using R, we would use the permTestAnova() function from CarletonStats package in R as follows:
** Permutation test **
Permutation test with alternative: greater
Observed F statistic: 0.89787
Mean of permutation distribution: 1.0044
Standard error of permutation distribution: 1.01157
P-value: 0.4127
*-------------*
Problem 2: Frisbee grip
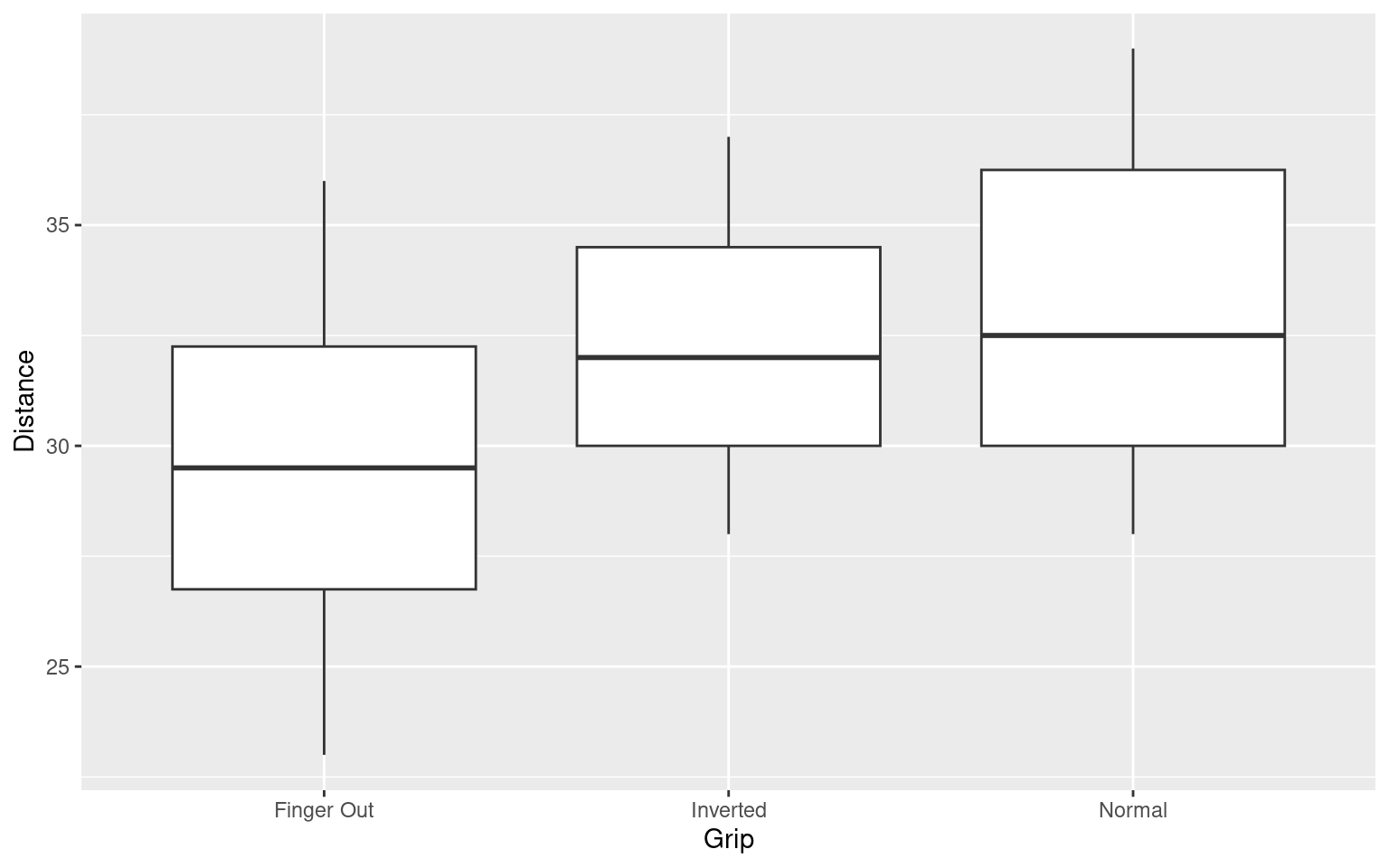
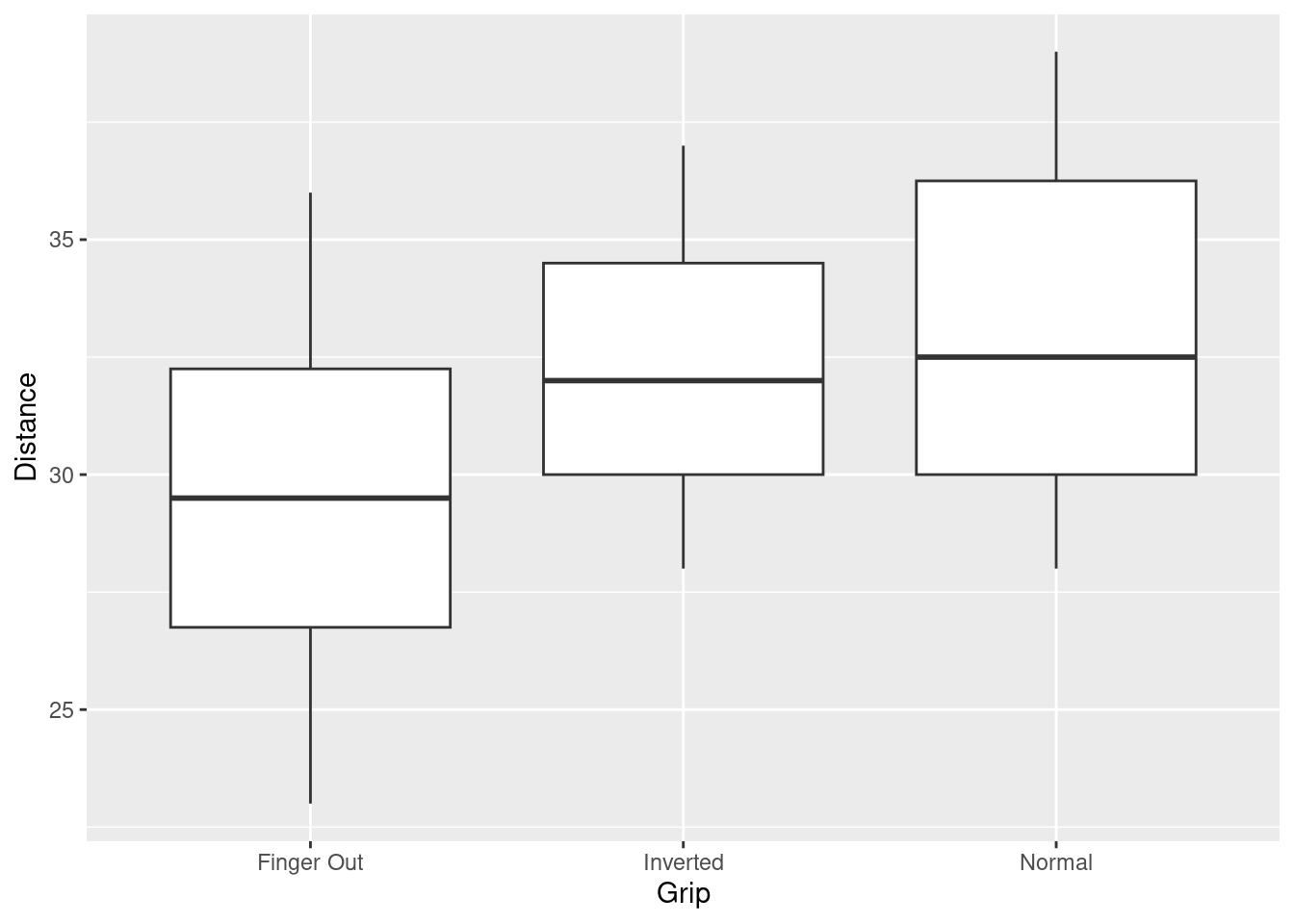
The data set Frisbee.csv contains data on Distance thrown (in paces) for three different frisbee Grip types. There are 24 difference cases (throws) Here we can compare responses to this question by the religiousness of the respondent:
frisbee <-read.csv("https://raw.githubusercontent.com/deepbas/statdatasets/main/Frisbee.csv")ggplot(frisbee, aes(x = Grip, y = Distance)) +geom_boxplot()
tapply(frisbee$Distance, frisbee$Grip, summary)
$`Finger Out`
Min. 1st Qu. Median Mean 3rd Qu. Max.
23.00 26.75 29.50 29.50 32.25 36.00
$Inverted
Min. 1st Qu. Median Mean 3rd Qu. Max.
28.00 30.00 32.00 32.38 34.50 37.00
$Normal
Min. 1st Qu. Median Mean 3rd Qu. Max.
28.00 30.00 32.50 33.12 36.25 39.00
The question we want to answer is whether or not the differences in observed mean distance thrown are statistically significant. To test this question comparing means for a quantitative response broken up into at least 2 groups, we can conduct a one-way ANOVA test.
(a) One-way ANOVA hypotheses
State the hypotheses for this test.
Click for answerAnswer: Let \(\mu\) be the true mean distance thrown using a certain grip. Then \(H_0: \mu_{fout} = \mu_{invert} = \mu_{normal}\) vs. \(H_A:\) at least one mean is different.
(b) One-way ANOVA test
You can obtain the one-way ANOVA table and test results with the aov(y ~ x, data=) command. Running the summary function on this anova result gives you the ANOVA table:
frisbee.anova <-aov(Distance ~ Grip, data = frisbee)summary(frisbee.anova)
Df Sum Sq Mean Sq F value Pr(>F)
Grip 2 58.58 29.29 2.045 0.154
Residuals 21 300.75 14.32
What is the F test stat value?
Click for answerAnswer:\(F = 2.045\)
Interpret the p-value.
Click for answerAnswer: If grip does not affect distance thrown, then we would see mean differences as larger, or larger, than those observed about 15.4% of the time.
What is your conclusion?
Click for answerAnswer: This study does not provide evidence that these three grips affect the mean distance thrown.
(c) Checking assumptions
Can we trust the p-value obtained above using the F distribution?
table(frisbee$Grip) # check n's
Finger Out Inverted Normal
8 8 8
tapply(frisbee$Distance, frisbee$Grip, sd) # similar SD's?
Finger Out Inverted Normal
4.174754 3.159453 3.943802
library(ggplot2) # shape?ggplot(frisbee, aes(x = Grip, y = Distance)) +geom_boxplot()
Click for answerAnswer: Sample sizes in all three groups are small (8) but the observed distances thrown within each group are roughly normally distributed. There are small differences in variation of the three groups, but the SD rule is met since largest SD (4.17) is less than twice the smallest SD (3.16). The assumptions are met.