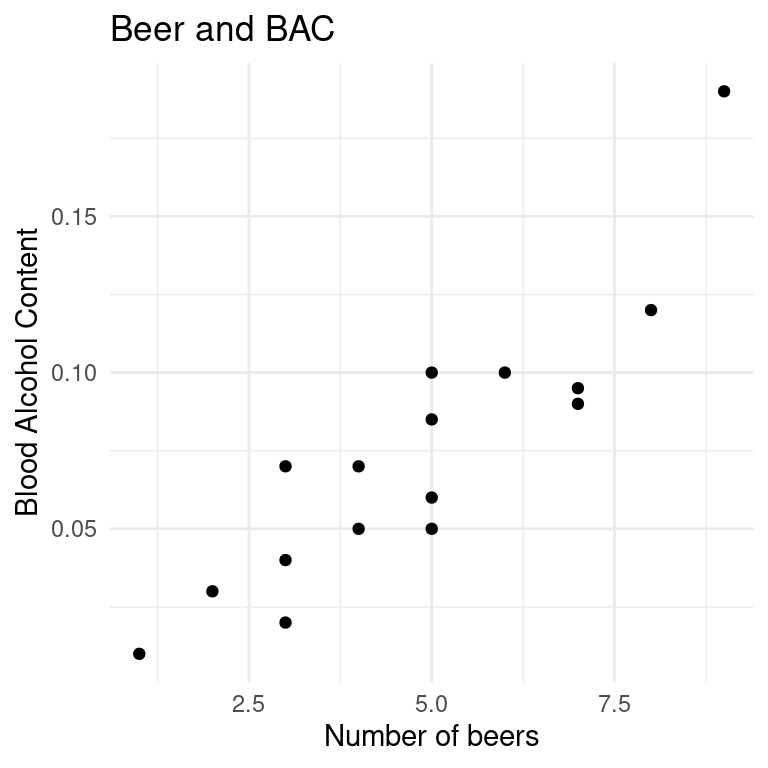
A study of 16 Ohio State University students looked at the relationship between the number of beers a student consumes and their blood alcohol content (BAC) 30 minutes after their last beer. The regression information from R to predict BAC from number of beers consumed is given below.
library(ggplot2); library(dplyr)bac <-read.csv("https://raw.githubusercontent.com/deepbas/statdatasets/main/BAC.csv")ggplot(data = bac, aes(x = Beers, y = BAC)) +geom_point(shape =19) +labs(title ="Beer and BAC", x ="Number of beers", y ="Blood Alcohol Content") +theme_minimal()
Is there a relationship?
direction?
strength?
form?
(a) Computing correlation
Compute correlation and account for missing values.
cor(bac$BAC, bac$Beers, use ="complete.obs")
[1] 0.8943381
Note: If there are any missing values (NA’s) on either of the variables involved in the correlation calculation, use use = "complete.obs" as an extra argument to the cor function.
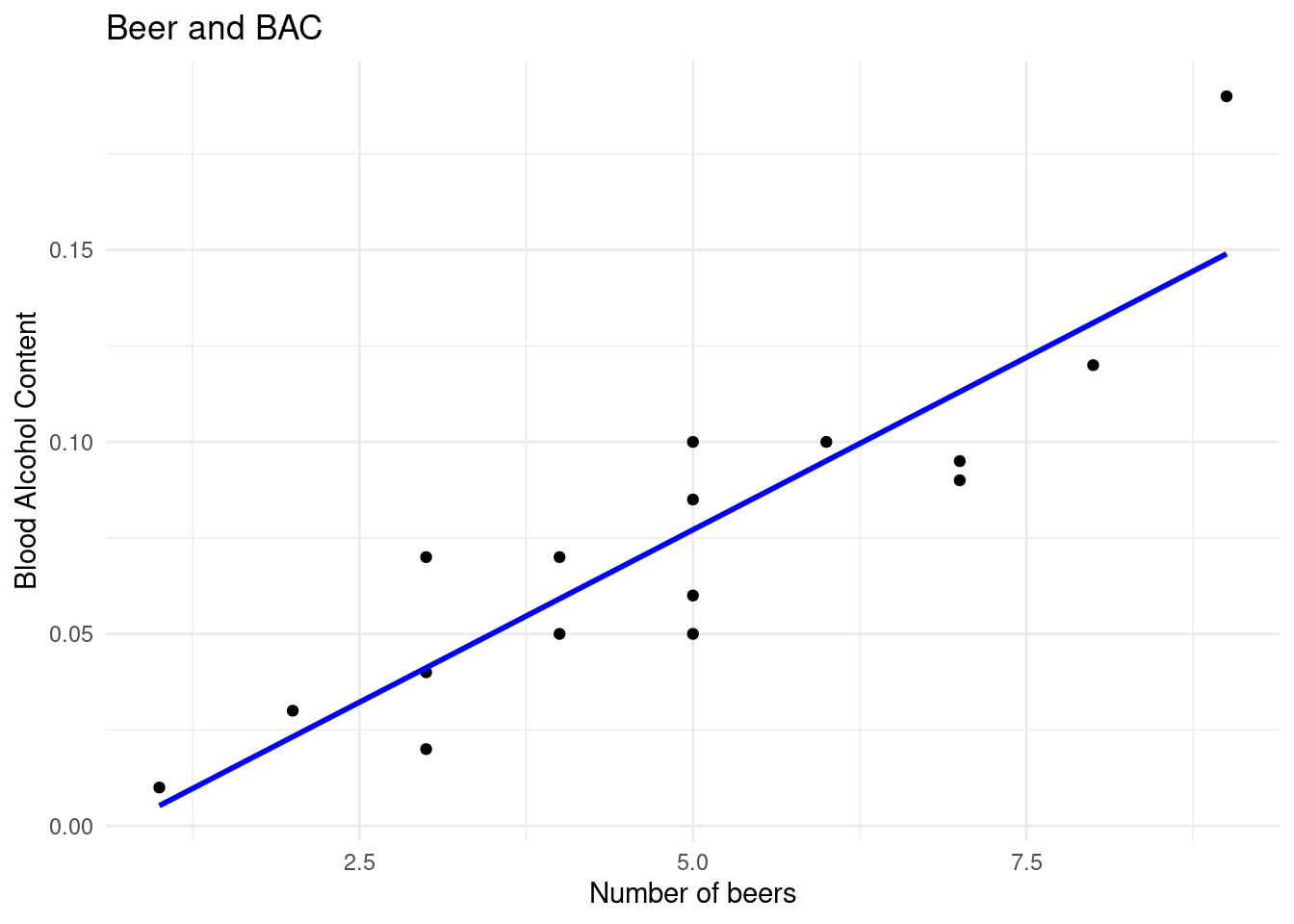
(b) Fitting a regression line
We use the lm(y ~ x, data=mydata) function to fit a linear (regression) model for a response y given an explanatory variable x. This command creates a linear model object that needs to be assigned a name, here we call it bac.lm. You can get the slope and intercept by typing out the object name:
(c) Write down the fitted regression equation to predict BAC from number of beers.
Click for answerAnswer:\(\hat{y} = -0.01270 + 0.01796*x\)
You can add this regression line to your scatterplot from part (a) by creating the plot and using the abline command:
ggplot(data = bac, aes(x = Beers, y = BAC)) +geom_point(shape =19) +geom_smooth(method ="lm", se =FALSE, color ="blue") +labs(title ="Beer and BAC", x ="Number of beers", y ="Blood Alcohol Content") +theme_minimal()
(d) Interpret the slope in context.
Click for answerAnswer: Drinking one more beer is associated with a 0.0180 unit increase in predicted BAC.
(e) Interpret the intercept in context, if it makes sense to do so.
Click for answerAnswer: The intercept is -0.0127. A student who drinks 0 beers would be predicted to have a negative blood alcohol content. This is not possible so the intercept does not make sense in this context, but the intercept is included in the model to get the best fit line for the data collected.
(f) If your friend at Ohio State drank 2 beers, what would you predict their BAC to be?
You can use the summary command on an lm object to get a more detailed print out of your linear model, along with the \(R^2\) value for your model:
summary(bac.lm)
Call:
lm(formula = BAC ~ Beers, data = bac)
Residuals:
Min 1Q Median 3Q Max
-0.027118 -0.017350 0.001773 0.008623 0.041027
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.012701 0.012638 -1.005 0.332
Beers 0.017964 0.002402 7.480 2.97e-06 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.02044 on 14 degrees of freedom
Multiple R-squared: 0.7998, Adjusted R-squared: 0.7855
F-statistic: 55.94 on 1 and 14 DF, p-value: 2.969e-06
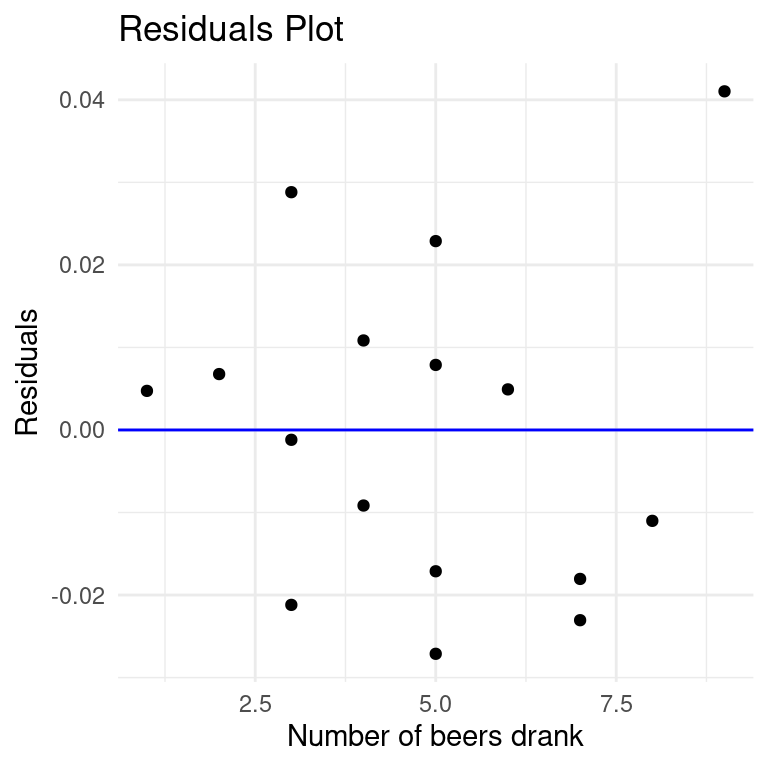
(j) Making a residuals plot
The regression of BAC on Beers has a residuals plot that plots the model’s residuals on the y-axis and the explanatory (“predictor”) on the x-axis. We add a horizontal reference line (the detrended regression line) with the geom_hline() command:
# code for residual plotggplot(data = residuals, aes(x = Beers, y = Residuals)) +geom_point(shape =19) +geom_hline(yintercept =0, color ="blue") +labs(title ="Residuals Plot",x ="Number of beers drank",y ="Residuals") +theme_minimal()
Interpret: There is one case of 9 beers with a large residual (much higher BAC than predicted), but since there is no clear pattern (trend) in this plot it looks like our regression model adequately describes the relationship between number of beers and BAC.
Is the magnitude of the scatter around the horizontal 0-line in the residuals plot greater than, less than, or the same as the magnitude of the scatter around the regression line in the scatterplot?
Click for answerAnswer: The same! The residuals plot is only a “detrended” scatterplot, meaning the vertical distances between a point and the regression line on the scatterplot or a point and the 0-line on the residuals plot are exactly the same. The residual plot looks more scattered because the trend is removed and the scale of the y-axis compressed.
(k) Identifying points
To find rows where the number of Beers is 9, we can use the filter function from the dplyr package.
# Use `filter` to find rows where Beers equals 9filtered_data <-filter(bac, Beers ==9)filtered_data
What is the row number of the case with the most negative residual? We could eyeball the graph to see that the most negative residual is less than -0.02:
To find the row number of the case with the most negative residual, you can identify residuals less than -0.02, and then pinpoint the one that also drank 5 beers:
# Use `filter` to identify rows with residuals less than -0.02 and 5 beersfiltered_resid <-filter(bac, resid(bac.lm) <-0.02& Beers ==5)filtered_resid
X ID_OSU Gender Weight Beers BAC
1 10 10 male 275 5 0.05
(l) Checking outlier influence
You can examine the influence of removing specific cases on your model by using the subset parameter in the lm function. For instance, to remove row 3:
# Fit a linear model without row 3bac.lm2 <-lm(BAC ~ Beers, data = bac, subset =-3)
# Compare the two modelssummary(bac.lm2)
Call:
lm(formula = BAC ~ Beers, data = bac, subset = -3)
Residuals:
Min 1Q Median 3Q Max
-0.023685 -0.010068 -0.003685 0.011985 0.027208
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 2.481e-05 1.088e-02 0.002 0.998
Beers 1.455e-02 2.216e-03 6.568 1.8e-05 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.01624 on 13 degrees of freedom
Multiple R-squared: 0.7684, Adjusted R-squared: 0.7506
F-statistic: 43.14 on 1 and 13 DF, p-value: 1.802e-05
summary(bac.lm)
Call:
lm(formula = BAC ~ Beers, data = bac)
Residuals:
Min 1Q Median 3Q Max
-0.027118 -0.017350 0.001773 0.008623 0.041027
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.012701 0.012638 -1.005 0.332
Beers 0.017964 0.002402 7.480 2.97e-06 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.02044 on 14 degrees of freedom
Multiple R-squared: 0.7998, Adjusted R-squared: 0.7855
F-statistic: 55.94 on 1 and 14 DF, p-value: 2.969e-06
After removing case 3, how has the slope changed? Explain the why the change occurred.
Click for answerAnswer: The slope drops from 0.0180 to 0.0146. Explanation given above.
After removing case 3, how has the \(R^2\) changed? Explain the why the change occurred.
Click for answerAnswer: The \(R^2\) descreases from 79.9% to 76.8%. This small decrease happens because case 3 actually enhances the overall linear trend and removing it results is a slight decrease to correlation and \(R^2\).
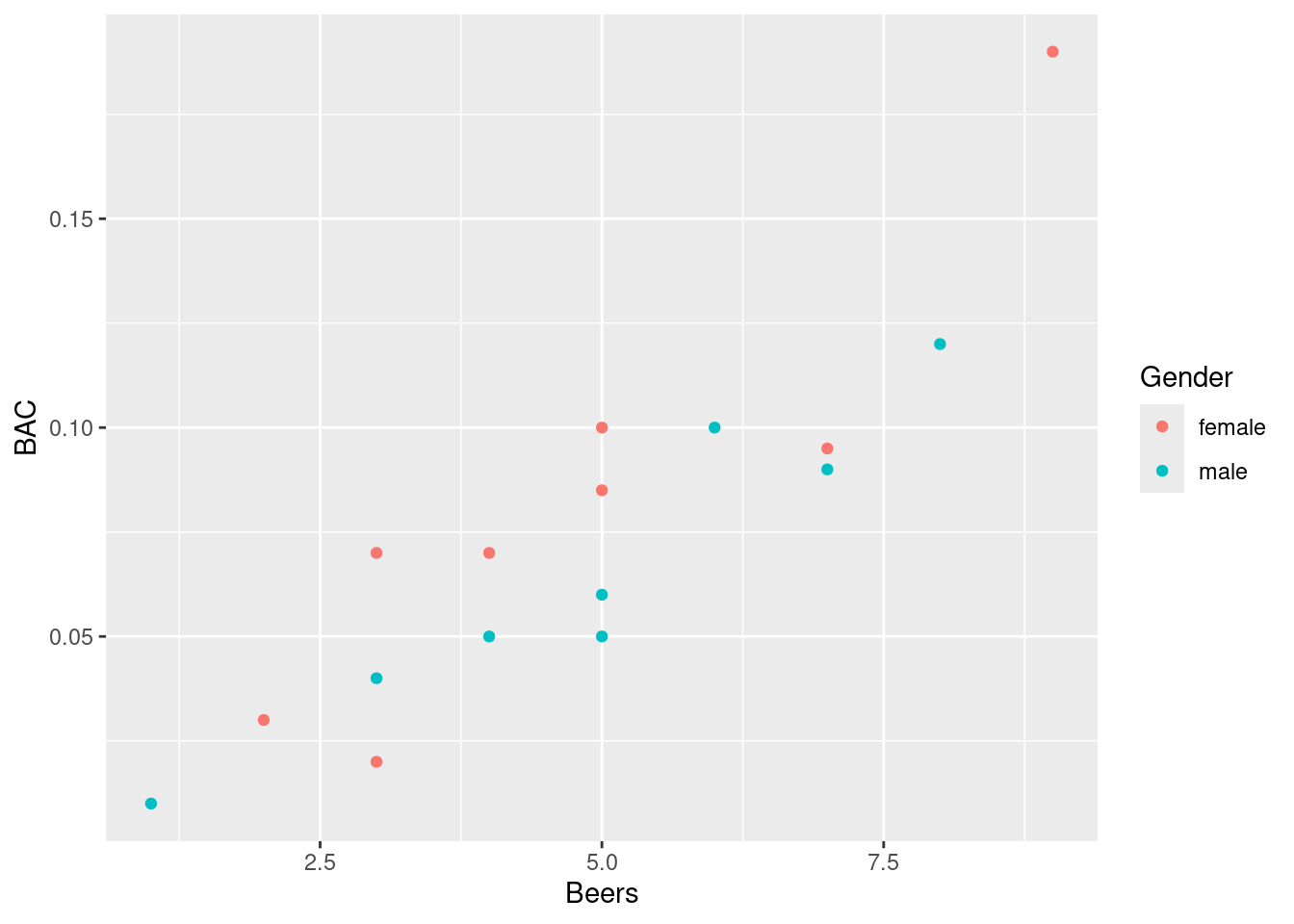
(m) Adding a categorical variable to your plot
To color-code points by a categorical variable like Gender, you can use the ggplot2 package as follows:
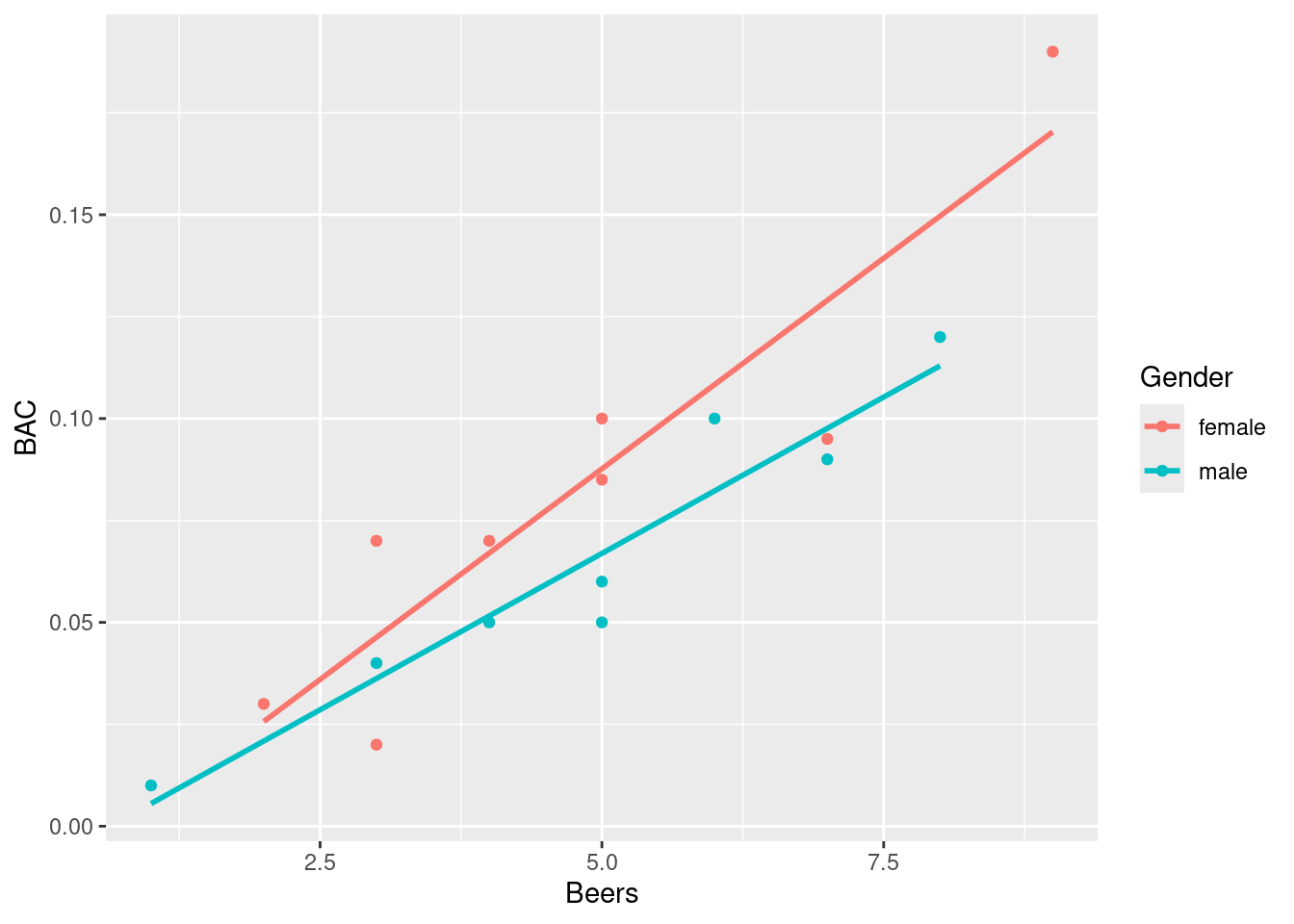
ggplot(bac, aes(x = Beers, y = BAC, color = Gender)) +geom_point()
Are the associations similar? (form, strength, direction)
Click for answerAnswer: Both females and males have similar strong, positive linear associations.
(n) Regression lines by groups
To investigate the relationship of Beers and BAC for different genders, we can fit separate linear models.
ggplot(bac, aes(x = Beers, y = BAC, color = Gender)) +geom_point() +geom_smooth(method ="lm", se=FALSE)
We can also investigate the mean and the standard deviations of the Blood Alcohol Content (BAC) for Males and Females using the following R functions:
# summary statistics of BAC by gender using dplyr group_by and summarizebac %>%group_by(Gender) %>%summarize(mean =mean(BAC),sd =sd(BAC))
# A tibble: 2 × 3
Gender mean sd
<chr> <dbl> <dbl>
1 female 0.0825 0.0521
2 male 0.065 0.0359
For Females:
# Use `filter` to get female databac_female <-filter(bac, Gender =="female")# Fit the model for femalesbac_lm_female <-lm(BAC ~ Beers, data = bac_female)summary(bac_lm_female)
Call:
lm(formula = BAC ~ Beers, data = bac_female)
Residuals:
Min 1Q Median 3Q Max
-0.034000 -0.008583 0.003667 0.014167 0.023667
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.015667 0.019008 -0.824 0.44135
Beers 0.020667 0.003641 5.676 0.00129 **
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.0223 on 6 degrees of freedom
Multiple R-squared: 0.843, Adjusted R-squared: 0.8168
F-statistic: 32.21 on 1 and 6 DF, p-value: 0.001289
For Males:
# Use `filter` to get male databac_male <-filter(bac, Gender =="male")# Fit the model for malesbac_lm_male <-lm(BAC ~ Beers, data = bac_male)summary(bac_lm_male)
Call:
lm(formula = BAC ~ Beers, data = bac_male)
Residuals:
Min 1Q Median 3Q Max
-0.016918 -0.007088 0.001093 0.005099 0.017742
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.009785 0.010323 -0.948 0.379786
Beers 0.015341 0.001947 7.881 0.000221 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.0115 on 6 degrees of freedom
Multiple R-squared: 0.9119, Adjusted R-squared: 0.8972
F-statistic: 62.11 on 1 and 6 DF, p-value: 0.0002211
What is the regression line for females? for males?
Click for answerAnswer: For females: \(\widehat{BAC} = -0.016 +0.021(BAC)\) and for males: \(\widehat{BAC} = -0.01 +0.015(BAC)\)
Which gender has the largest slope? What does this suggest about the relationship between number of beers and BAC for this gender?
Click for answer
Answer: The slope for females is slightly higher. This shows that the effect of one more beer on predicted BAC in females is larger than males (a 0.021 increase vs. a 0.015 increase).
Problem 2: Inkjet Example
The following Inkjet dataset deals with 20 observations on the following 6 variables:
Model Model name of printer
PPM Printing rate (pages per minute) for a benchmark set of print jobs
PhotoTime Time (in seconds) to print \(4 \times 6\) color photos
Price Typical retail price (in dollars)
CostBW Cost per page (in cents) for printing in black & white
CostColor Cost per page (in cents) for printing in color
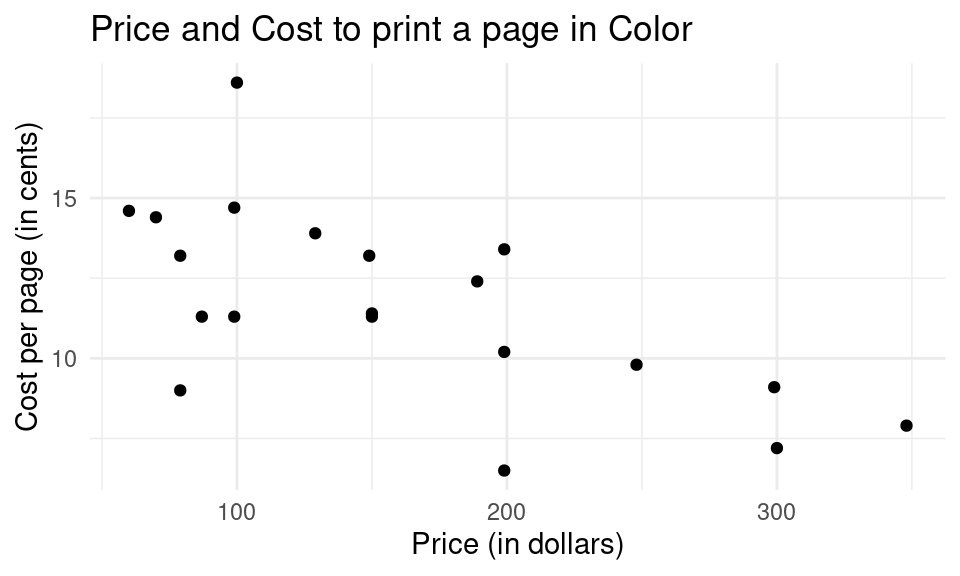
ggplot(data = inkjet, aes(x = Price, y = CostColor)) +geom_point(shape =19) +labs(title ="Price and Cost to print a page in Color",x ="Price (in dollars)",y ="Cost per page (in cents)") +theme_minimal()
(a) Is there a relationship?
+ direction?
+ strength?
+ form?
Click for answerAnswer: There is a negative, moderate, and linear relationship.
We use the lm(y ~ x, data=mydata) function to fit a linear (regression) model for a response y given an explanatory variable x.
Answer: For each dollar increase in the price of the inkjet printer, there is a decrease in the cost to print in color by 0.02278 cents.
(d) Interpret the intercept in context, if it makes sense to do so.
Click for answer
Answer: For a price of printer that costs 0 dollars, the cost to print in color is 15.3514 cents. It is an extrapolation and it’s nonsensical to talk about a printer costing 0 dollars in this context.
(f) If you buy an injet printers worth 200 dollars, what would you estimate the cost per page (in cents)?
Click for answer
Answer: The cost per page would be 10.80 cents.
15.3514-0.02278*200
[1] 10.7954
(g) What is the value of \(R^2\), the coefficient of determination? What does it mean?
Click for answer
Answer: The value of \(R^2\) is 0.4228. It means that about 42.28% of variability in the cost to print in color is explained by the price of the inkjet printer.
(h) What is the value of \(r\), the correlation coefficient?
Click for answer
Answer: The value of \(r\) is - 0.65.
-sqrt(0.4228)
[1] -0.6502307
Note: It’s important to note that \(R^2\) and \(r\) are related but not directly convertible just by taking a square root, especially in multiple regression scenarios. The square root of \(R^2\) only equals \(r\) in simple linear regression models, and even then, the sign of \(r\) depends on the sign of the slope.