prices <- c(132,87, 185, 52, 23, 147, 125, 93, 85, 72)
mean(prices)[1] 100.1Prices of a random sample of 10 textbooks (rounded to the nearest dollar) are shown:
\[ \$132 \quad \$87 \quad \$185 \quad \$52 \quad \$23 \quad \$147 \quad \$125 \quad \$93 \quad \$85 \quad \$72 \]
prices <- c(132,87, 185, 52, 23, 147, 125, 93, 85, 72)
mean(prices)[1] 100.1Answer: We use 10 cards and write the 10 sample values on the cards. We then mix them up and draw one and record the value on it and put it back. Mix them up again, draw another, record the value, and put it back. Do this 10 times to get a “with replacement” sample of size 10. Then compute the sample mean of this bootstrap sample.
resample <- sample(prices, replace = TRUE)
resample [1] 132 93 72 132 132 85 23 23 147 125Will the mean of this resample be same as the original sample? What about the standard deviation?
Answer: The mean of the resample, created using bootstrapping, could be the same, more than, or less than the mean of the original sample, depending on which values are randomly chosen during the resampling process. Bootstrapping involves randomly selecting observations from the original sample with replacement, so there’s a chance the resample might have more of the higher values, more of the lower values, or a mix similar to the original sample.
As for the standard deviation, it also depends on the composition of the resampled data. If the resample ends up with values that are close to each other (less variability), its standard deviation might be lower than the original sample. Conversely, if the resample has a wider spread of values, the standard deviation could be higher. However, over many bootstrap samples, the average standard deviation will tend to be close to the standard deviation of the original sample.
Answer: It will be centered approximately at the sample mean of 100.1 and we expect it to be roughly bellshaped (it may be a bit skewed since the sample size of 10 is smallish).
boot from CarletonStats R package creates a bootstrap distribution from the original sample of 10 textbook prices. What is the standard error of this bootrtrap distribution. Will this standard error be smaller or larger than the standard deviation of the original sample? Explain.library(CarletonStats)
boot(prices)
** Bootstrap interval for mean
Observed prices : 100.1
Mean of bootstrap distribution: 100.0944
Standard error of bootstrap distribution: 14.19988
Bootstrap percentile interval
2.5% 97.5%
72.6975 127.8025
*--------------*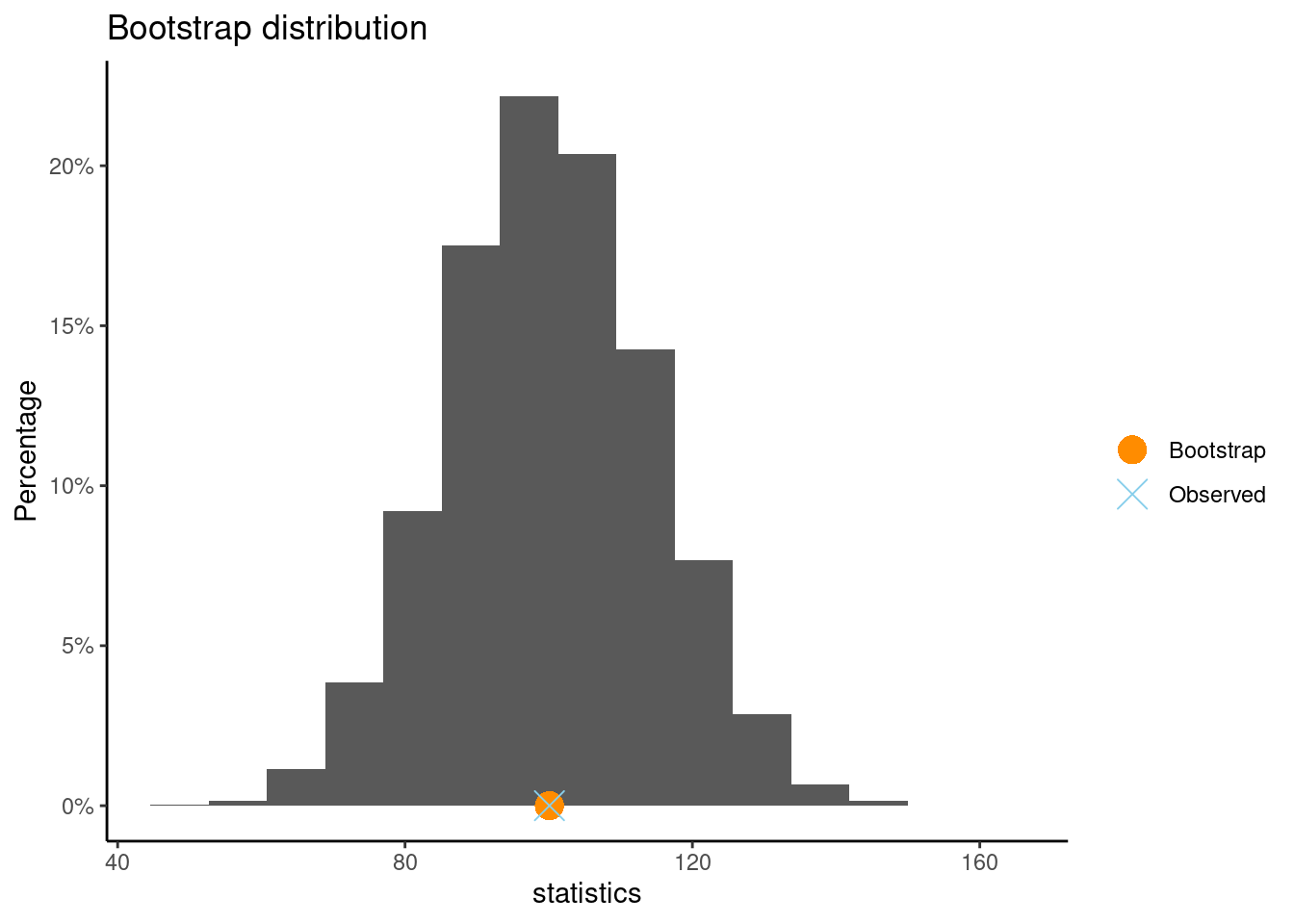
Answer: This standard error will typically be smaller than the standard deviation of the original sample because the standard error is estimating the variability of the sample mean, not individual observations. The sample mean tends to have less variability than individual data points, especially when averaged across multiple samples.
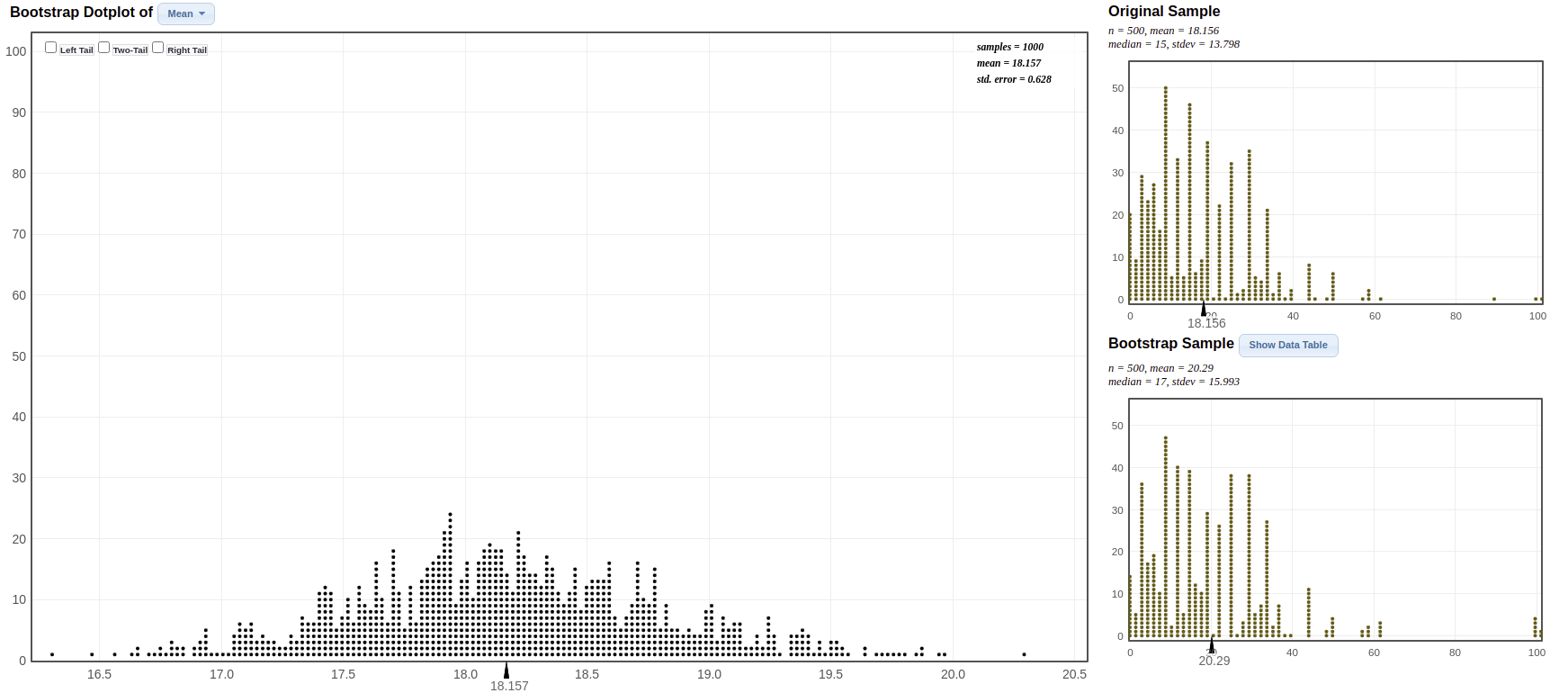
Go to the website at Lock5Statkey. Under the “Bootstrap Confidence Intervals” column, select the “CI for Single Mean, Median, St.Dev”. Change the data set to Atlanta Commute (Distance). This data set gives a random sample of 500 worker commute distances (miles) for metropolitan Atlanta
Answer: The sample mean is \(\bar{x} = 18.16\) and the sample standard deviation is \(s = 13.798\).
Answer: The bootstrap sample was obtained by resampling from the 500 observed commute distances with replacement. Basically we randomly select 500 distances from the data (with replacement).
The value of the bootstrap mean will vary.Answer: The bootstrap distribution is always centered around the statistic that is being bootstrapped. Here it will be centered around the sample mean commute distance of about 18.16 miles. The population mean commute distance is unknown!
What percentage of Americans believe in global warming? A survey on 2,251 randomly selected individuals conducted in October 2010 found that 1,328 answered Yes to the question “Is there solid evidence of global warming?” To compute a bootstrap confidence interval for the proportion of all Americans who believe in global warming, go to the website at Lock5Statkey. Under the “Bootstrap Confidence Intervals” column, select the “CI for Single Proportion”.
Answer: The shape is symmetric around a center value of about 0.59, which is the sample proportion not the population proportion (which is unknown).
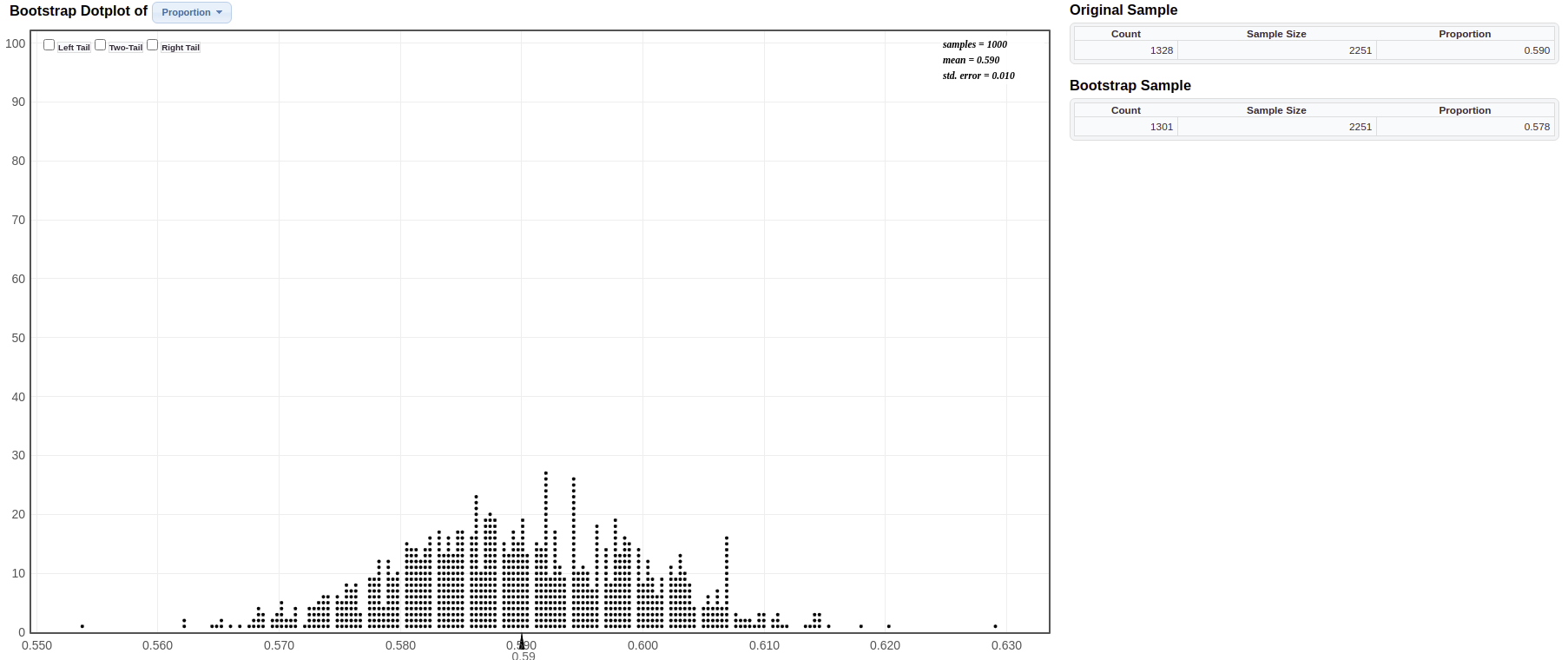
Answer: Yes, the data does support this claim since we are confident that at least 50% of Americans believe in global warming since the lower bound on the CI is 57%.
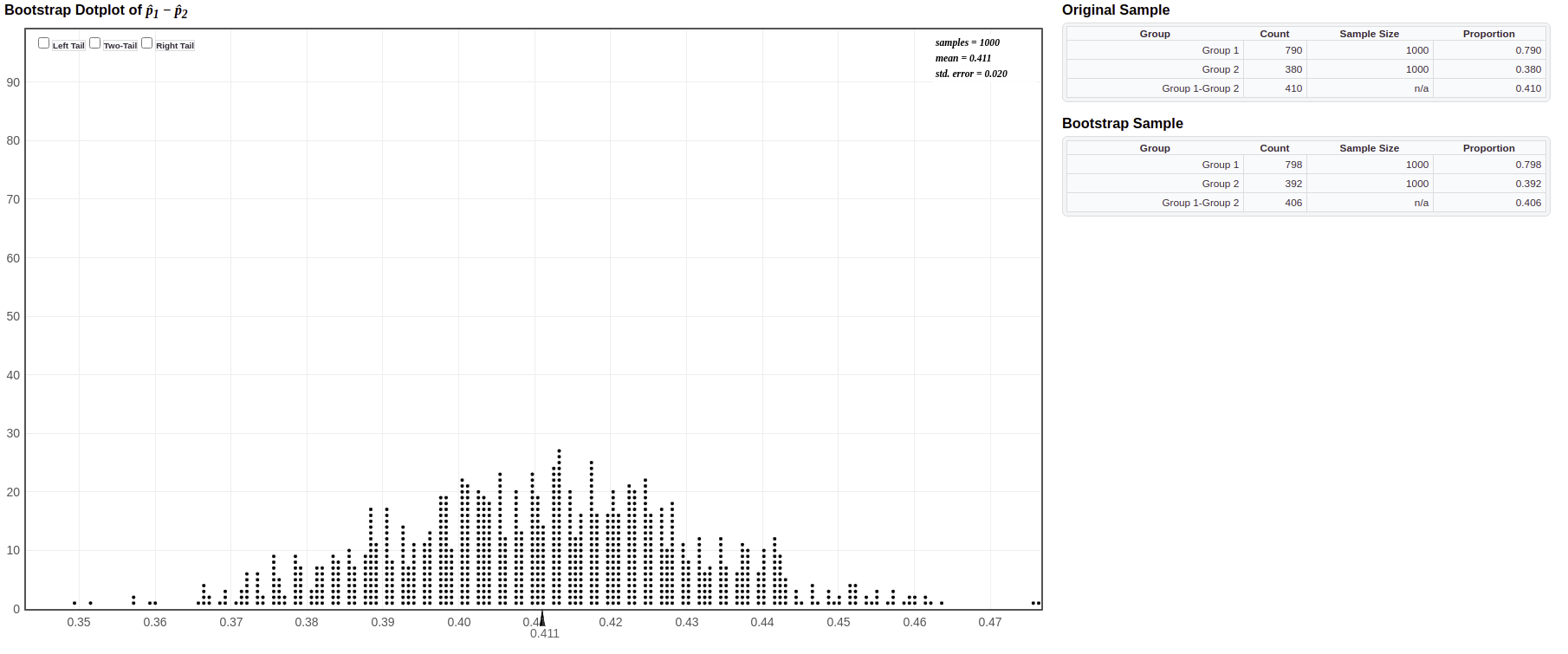
Does belief in global warming differ by political party? When the question “Is there solid evidence of global warming?” was asked, the sample proportion answering “yes” was 79% among Democrats and 38% among Republicans. To compute a bootstrap confidence interval for the difference in the proportion of Democrats and Republicans who believe in global warming, go to the website at Lock5Statkey. Under the “Bootstrap Confidence Intervals” column, select the “CI for Difference in Proportions”.
Answer: One bootstrap sample was obtained from the group 1 sample (resampling the observed “believe/not believe” responses with replacement) and a separate bootstrap sample was obtained from the group 2 sample. The difference in the bootstrap proportions for each group was computed for the bootstrap difference statistic.
For individual bootstrap samples: answers will vary.Answer: The shape is symmetric around a center value of about 0.41 (the sample difference in proportions).
The data set CreditData.csv contains records for 1000 loans that either defaulted (BadLoan) or did not default (GoodLoan). There are 300 loans that defaulted and 700 that did not. Let’s consider that the 300 loans that defaulted are random sample of loans that default and the 700 non-defaulting loans are a random sample of loans that don’t default.
credit <- read.csv("https://raw.githubusercontent.com/deepbas/statdatasets/main/CreditData.csv")
table(credit$Good.Loan)
BadLoan GoodLoan
300 700 The variable Age.in.years gives the age of the person who received the loan. Construct a side-by-side boxplot of age by Good.Loan and compute the sample means for each group.
library(ggplot2)
ggplot(credit, aes(x = Good.Loan, y = Age.in.years)) +
geom_boxplot()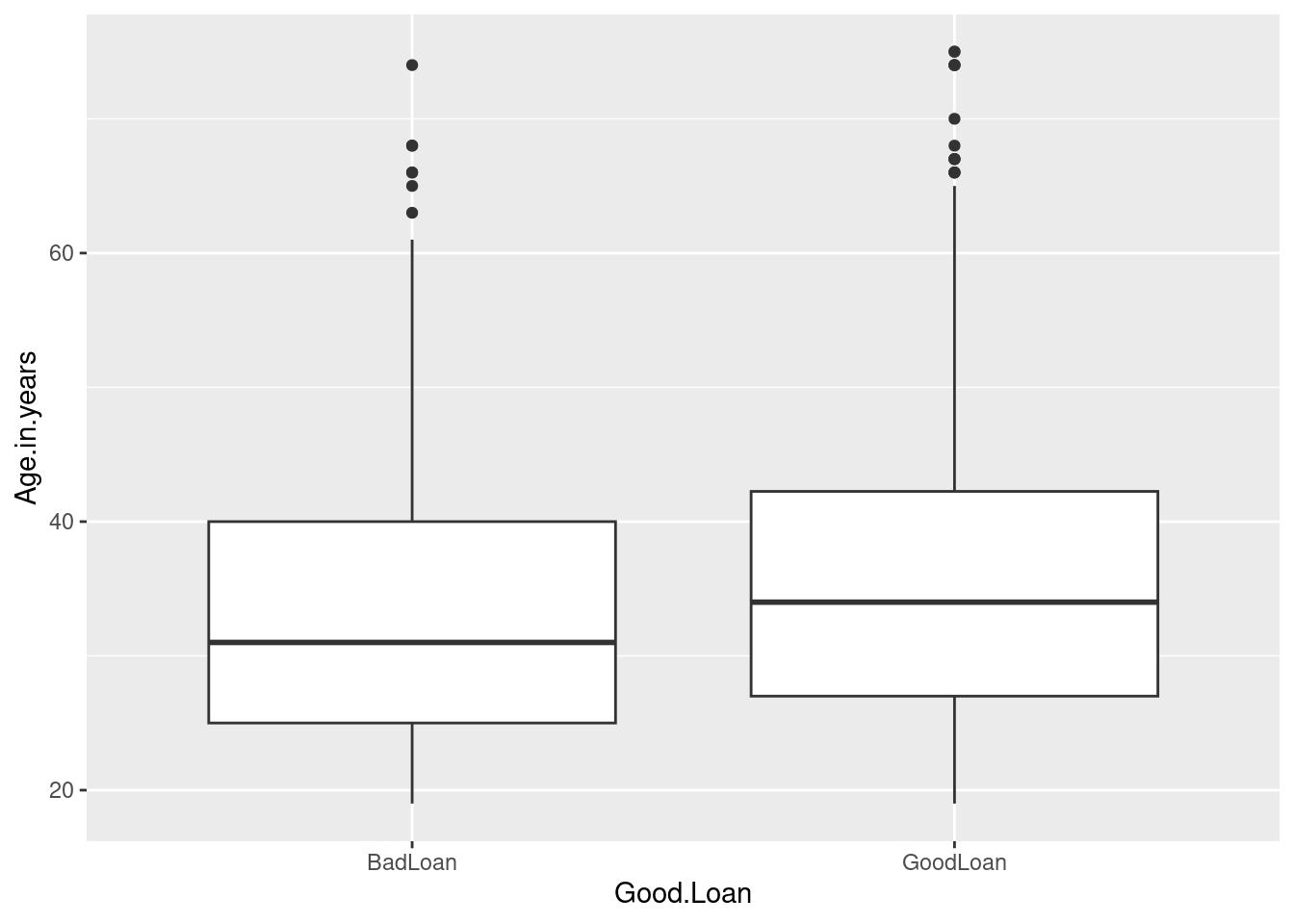
library(dplyr)
credit %>%
group_by(Good.Loan) %>%
summarize(mean_age = mean(Age.in.years))# A tibble: 2 × 2
Good.Loan mean_age
<chr> <dbl>
1 BadLoan 34.0
2 GoodLoan 36.2The boot(y ~ x, data=) command generates 10000 bootstrap samples for the true difference in means of y for each of the two groups in x. The command is contained in the CarletonStats package. Here we use it to compute the bootstrap distribution for the difference in mean ages of the two default groups:
library(CarletonStats)
boot(Age.in.years ~ Good.Loan, data=credit)
** Bootstrap interval for difference of mean
Observed difference of mean : BadLoan - GoodLoan = -2.26095
Mean of bootstrap distribution: -2.26661
Standard error of bootstrap distribution: 0.77264
Bootstrap percentile interval
2.5% 97.5%
-3.7652738 -0.7046905
*--------------*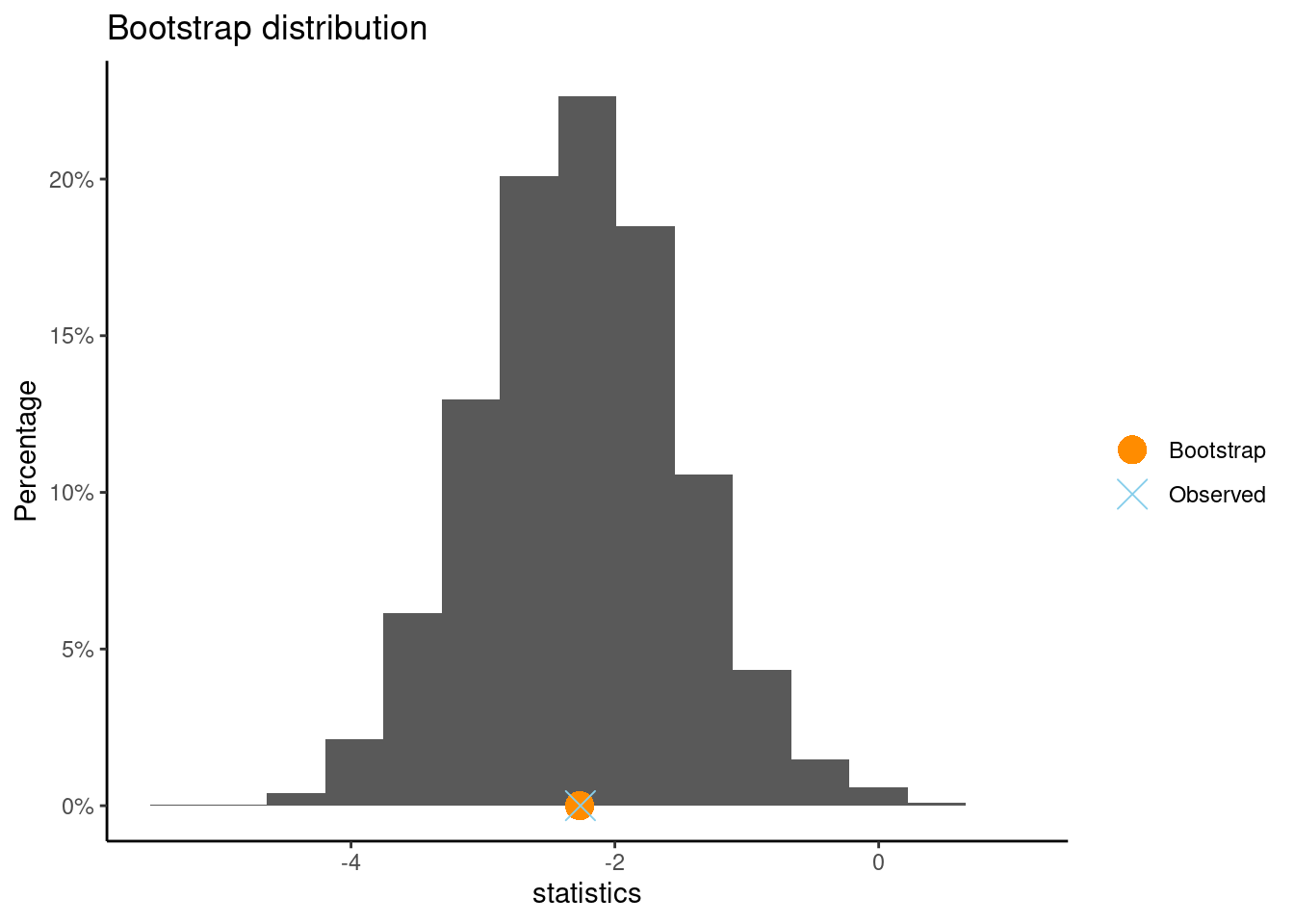
Answer: The CI using the SE is -3.8 to -0.7. The intervals are very similar.
\[ -2.26095 \pm 2(0.77852) = (-3.81799, -0.70391) \]
-2.26095 - 2*(0.77852)[1] -3.81799-2.26095 + 2*(0.77852)[1] -0.70391The variable Telephone tells us if the individual has a phone number on their loan file. Let’s look at the proportion of individuals who have a phone number for each type of loan (default or not).
The entries in the Telephone column are either none or yes, registered under the customers name.
table(credit$Telephone)
none
596
yes, registered under the customers name
404 # Modify the Telephone variable levels using dplyr and forcats
credit <- credit %>%
mutate(Telephone = recode(Telephone,
"none" = "no",
"yes, registered under the customers name" = "yes"))
# Convert the Telephone variable to a factor
credit$Telephone <- as.factor(credit$Telephone)
# Display the levels of the modified Telephone variable
levels(credit$Telephone)[1] "no" "yes"Here we get the distribution of phone numbers (yes or no) by default type (good vs bad loan):
prop.table(table(credit$Good.Loan, credit$Telephone),1)
no yes
BadLoan 0.6233333 0.3766667
GoodLoan 0.5842857 0.4157143library(ggplot2)
ggplot(credit, aes(x=Good.Loan, fill=Telephone)) + geom_bar(position="fill")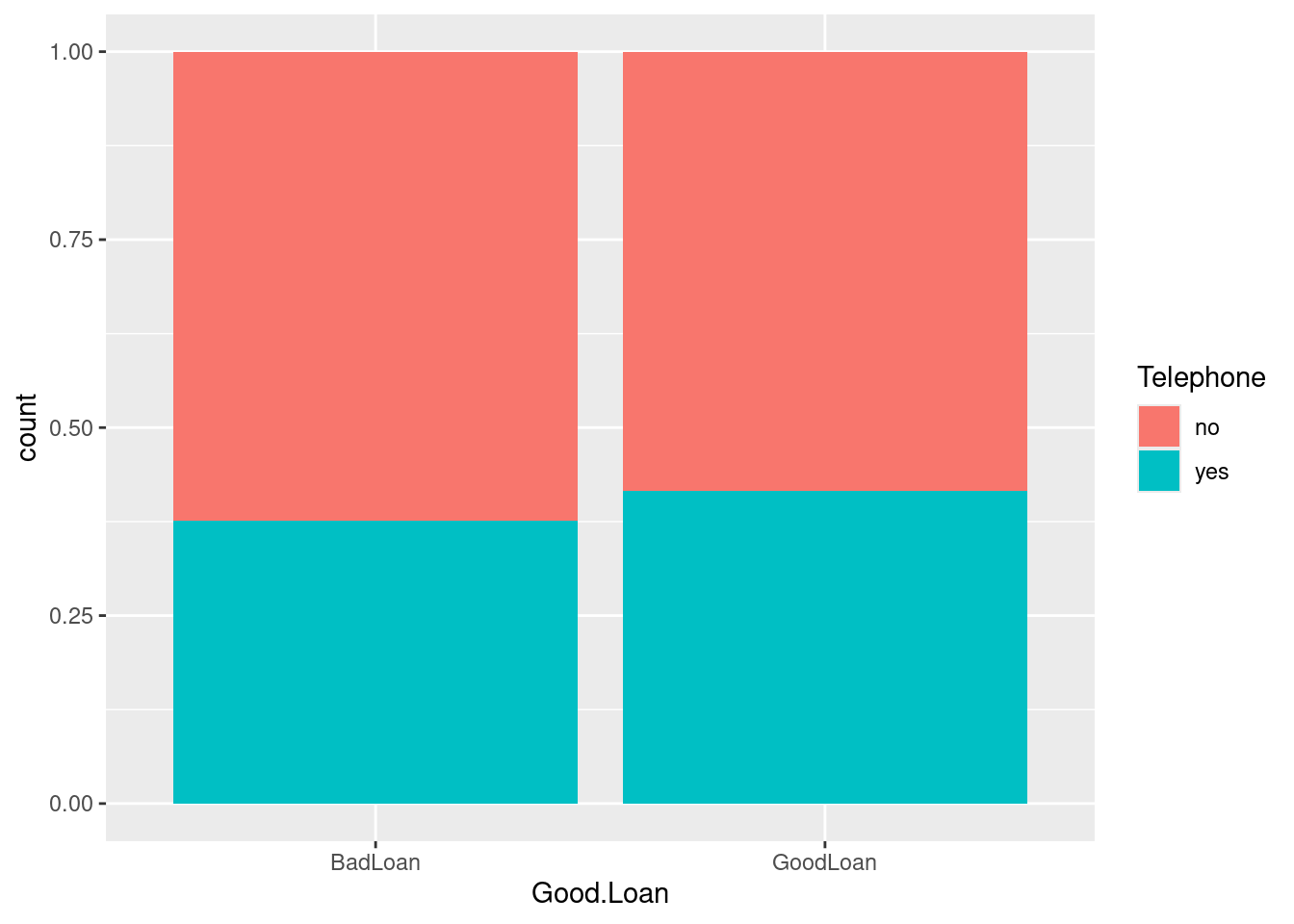
0.4157143 - 0.3766667[1] 0.0390476boot command with a categorical responseIn order to get the bootstrap distribution for the sample difference in proportions, we need to recode the “response” variable Telephone to have a 1 indicating a “yes” response and 0 indicating a “no” response. This is done with an ifelse command:
credit$Telephone_binary<- ifelse(credit$Telephone == "yes", 1, 0)
head(credit[,c("Telephone", "Telephone_binary")]) Telephone Telephone_binary
1 yes 1
2 no 0
3 no 0
4 no 0
5 no 0
6 yes 1which reads “if Telephone equals yes than assign a 1, else assign a 0”. These 0’s and 1’s are assigned to a variable called Telephone_binary that is now in your data frame (checked this with the View(credit) command).
Check your work to make sure Telephone_binary records what you want it to record
table(credit$Telephone)
no yes
596 404 table(credit$Telephone_binary)
0 1
596 404 The mean of the 0/1 coded variable computes the proportion of “yes” responses:
mean(credit$Telephone_binary)[1] 0.404404/1000 # proportion of yes[1] 0.404Note: All examples in your Lab Manual already have this 0/1 recoding done in the lab manual data sets. But I thought you might want to learn how to do this recoding in case you plan to use this command with other, non-lab manual data sets!
We can now use the 0/1 version of telephone in the boot command (like example 1) to compute a 95% bootstrap confidence interval for the difference in the population proportion of good loans and bad loans that have a phone number.
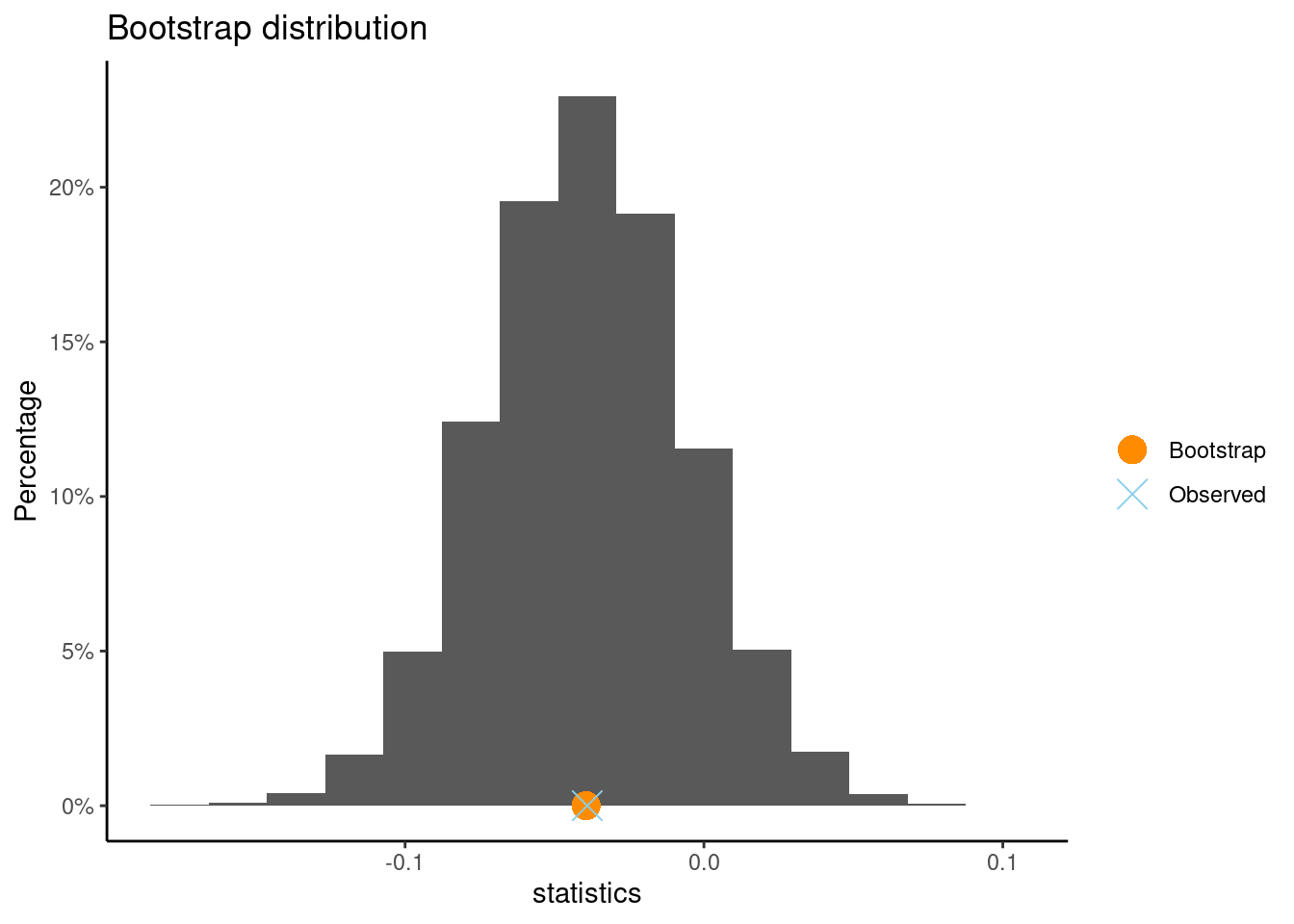
boot(Telephone_binary ~ Good.Loan, data=credit)
** Bootstrap interval for difference of mean
Observed difference of mean : BadLoan - GoodLoan = -0.03905
Mean of bootstrap distribution: -0.03945
Standard error of bootstrap distribution: 0.03373
Bootstrap percentile interval
2.5% 97.5%
-0.10523810 0.02761905
*--------------*
Even though the language used in the output says “statistic” we are computing a difference in “proportions”!!
-0.03905 - 2* 0.03373 [1] -0.10651-0.03905 + 2* 0.[1] -0.03905