jurors <- read.csv("https://raw.githubusercontent.com/deepbas/statdatasets/main/APM_DougEvansCases.csv")Practice Problems 4
Problem 1: Flowers v. Mississippi
The data set APM_DougEvensCases.csv contains data from 1517 potential black and white jurors for 66 cases that Doug Evans was primary prosecutor for between 1992 and 2017. These jurors were available for Doug Evans to strike using his “peremptory strikes” during the jury selection phase.
(a). Inspect data
Read in the data
# dimension of dataset
dim(jurors)[1] 1517 6Look at the first three rows of the data set
jurors[c(1,2,3), ] trial__id race struck_state defendant_race same_race
1 4 Black Not struck by State White different race
2 4 Black Struck by State White different race
3 4 White Not struck by State White same race
struck_by
1 Juror chosen to serve on jury
2 Struck by the state
3 Juror chosen to serve on juryTo get the data from one variable, we use the command dataset$variable. For example, jurors$struck_state gives us the data values from the struck_state variable, which tells us if a juror was struck by the state from the jury pool. Here we can see the first 10 entries in this variable:
jurors$struck_state[1:10] [1] "Not struck by State" "Struck by State" "Not struck by State"
[4] "Not struck by State" "Struck by State" "Not struck by State"
[7] "Struck by State" "Not struck by State" "Not struck by State"
[10] "Not struck by State"(b). Table of counts and proportions
The summary command used with a data frame gives summaries of each variable
summary(jurors) trial__id race struck_state defendant_race
Min. : 4.0 Length:1517 Length:1517 Length:1517
1st Qu.: 52.0 Class :character Class :character Class :character
Median : 82.0 Mode :character Mode :character Mode :character
Mean :112.6
3rd Qu.:170.0
Max. :301.0
same_race struck_by
Length:1517 Length:1517
Class :character Class :character
Mode :character Mode :character
The table command gives the distribution of counts for a single categorical variable. To obtain the count table for struck_state you need to
counts <- table(jurors$struck_state)
counts
Not struck by State Struck by State
1084 433 We can add the prop.table command to turn these counts into proportions:
prop.table(counts)
Not struck by State Struck by State
0.7145682 0.2854318 - What proportion of eligible jurors were struck by the state from the jury pool?
Click for answer
Answer: about 28.5% of eligible jurors were struck by the state.
(c). Bar graph for one variable
We can create a data frame count_data containing the counts and their corresponding categories.
count_data <- data.frame(counts)
count_data Var1 Freq
1 Not struck by State 1084
2 Struck by State 433Then, we use ggplot2 to create a bar plot with the categories on the x-axis and the counts on the y-axis. The column names of count_data are automatically assigned to be Var1 and Freq. We can change the column names to category and count, for example, as:
colnames(count_data) = c("category", "count")
count_data category count
1 Not struck by State 1084
2 Struck by State 433The geom_bar(stat = "identity") function is used to create the bars, and we set the y-axis label using labs().
# Create a bar plot using ggplot2
library(ggplot2) # load the package
ggplot(count_data, aes(x = category, y = count)) +
geom_bar(stat = "identity") +
labs(y = "count")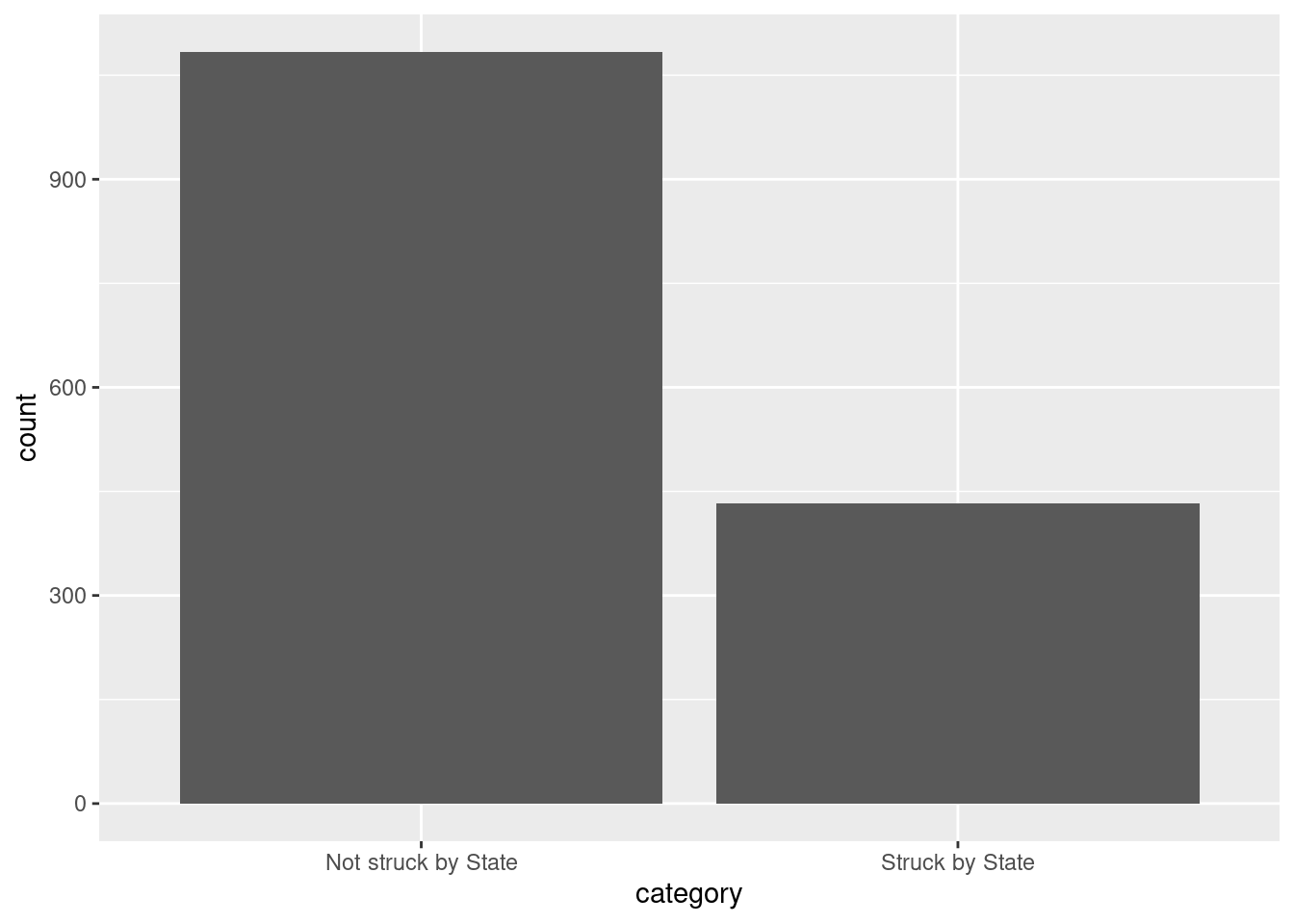
You may simply use geom_bar if the count data is not available.
ggplot(jurors, aes(x = struck_state)) + geom_bar() + ylab("Count")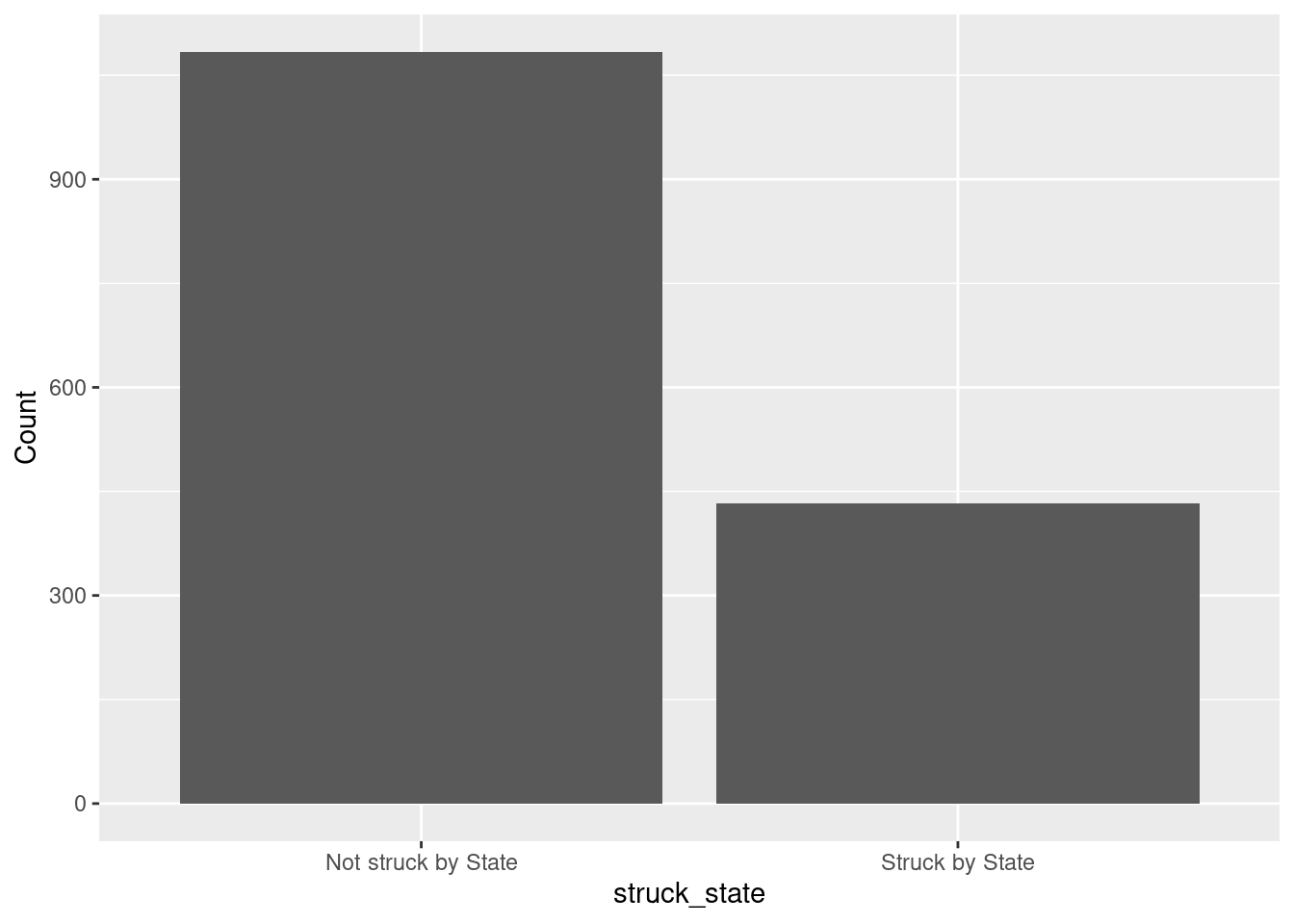
(d). Two-way tables
First 10 entries of race and struck_state variable is
jurors[(1:10),(2:3)] race struck_state
1 Black Not struck by State
2 Black Struck by State
3 White Not struck by State
4 White Not struck by State
5 Black Struck by State
6 White Not struck by State
7 Black Struck by State
8 White Not struck by State
9 White Not struck by State
10 White Not struck by StateThe table command also gives two-way tables when two variables are included. Here is the two-way table for juror race and state struck status:
mytable <- table(jurors$race, jurors$struck_state)
mytable
Not struck by State Struck by State
Black 225 310
White 859 123- How many jurors were white and were not struck by the state?
Click for answer
answer: 859
(e). Conditional proportions: state strike status by juror race
The prop.table command gives conditional proportions for a two-way table. We plug our two-way table into prop.table with a margin=1 to get proportions grouped by the row variable:
prop.table(mytable, margin = 1)
Not struck by State Struck by State
Black 0.4205607 0.5794393
White 0.8747454 0.1252546Of all eligible black jurors, about 57.9% were struck by the state.
- What proportion of eligible white jurors were struck by the state?
Click for answer
answer: about 12.5%
- Is there evidence of an association between juror race and state strikes?
Click for answer
answer: Yes, there is an association because the rate of state strikes varies greatly by juror race with about 60% of black jurors were struck compared to only 13% of white jurors
(f). Stacked bar graph for two variables
We can visualize the conditional distribution from part (e) with a stacked bar graph created using the ggplot2 graphing package. First, load this package’s functions with the library command:
library(ggplot2)Now we can use the geom_bar command in this package. Here we get the conditional distribution of struck_state given race:
ggplot(jurors, aes(x = race, fill = struck_state)) +
geom_bar(position = "fill") +
labs(title = "State strikes by juror race", y = "proportion",
x = "eligible juror race", fill = "struck by state?")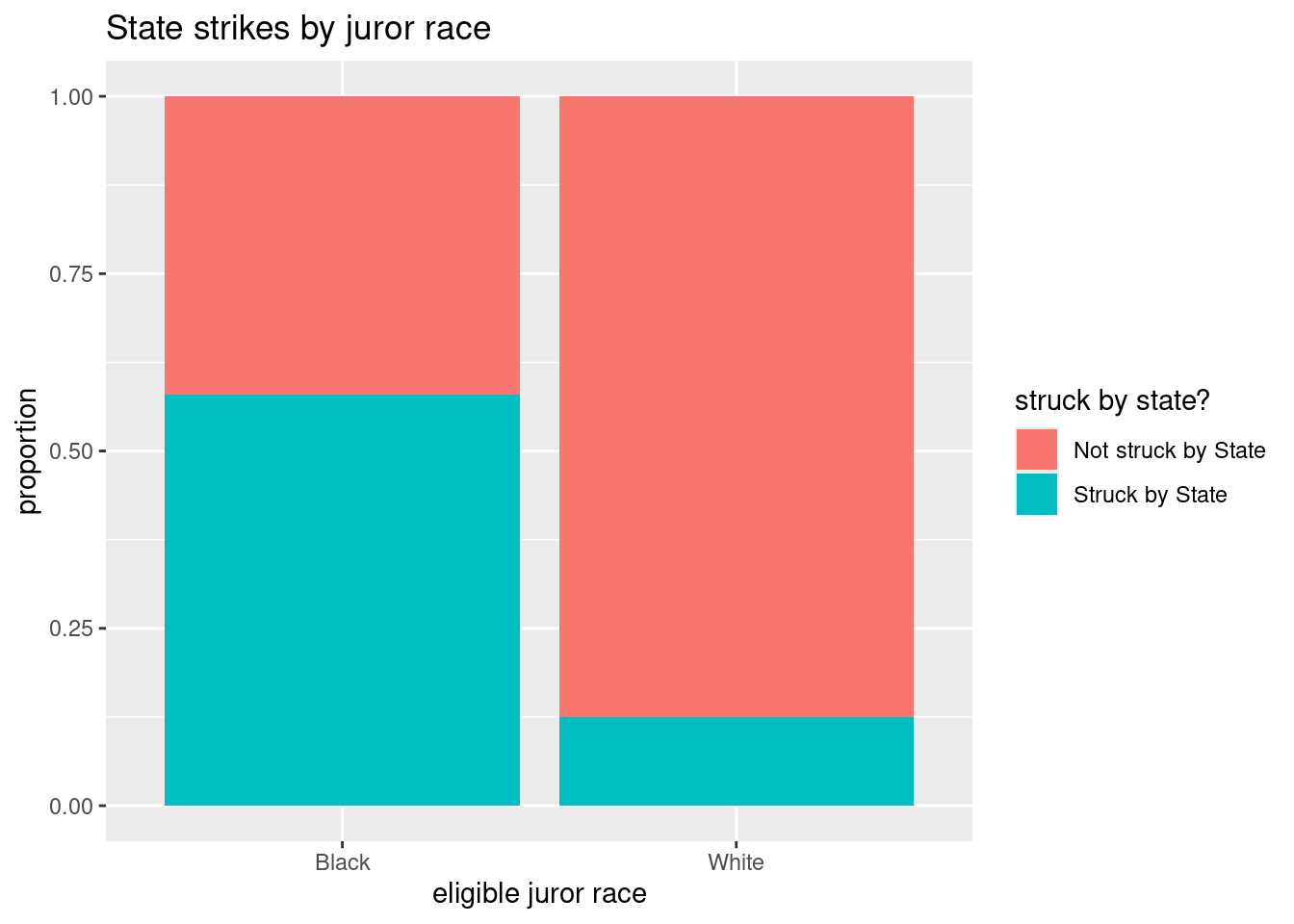
The basic syntax for this function is to let ggplot know your data set name (jurors), then specify the grouping or conditional variable on the x-axis (race) in the aes (aesthetic) argument. The fill variable is the response variable (struck_state). We add (+) the geom_bar geometry to get a bar graph with the fill position specified. Adding an informative label and title complete the graph.
(g). Conditional distribution of race grouped by strike status
We can “flip” our response and grouping variables easily (if we think it makes sense to do so). Here we specify the margin=2 to get proportions grouped by the column variable:
prop.table(mytable, margin = 2)
Not struck by State Struck by State
Black 0.2075646 0.7159353
White 0.7924354 0.2840647Notice that the proportions add to one down each column. Of all eligible jurors struck by the state, about 71.6% were black.
The stacked bar graph for this distribution is
ggplot(jurors, aes(x = struck_state, fill = race)) +
geom_bar(position = "fill") +
labs(title = "Juror race by state strikes", y = "proportion",
fill = "eligible juror race", x = "struck by state?")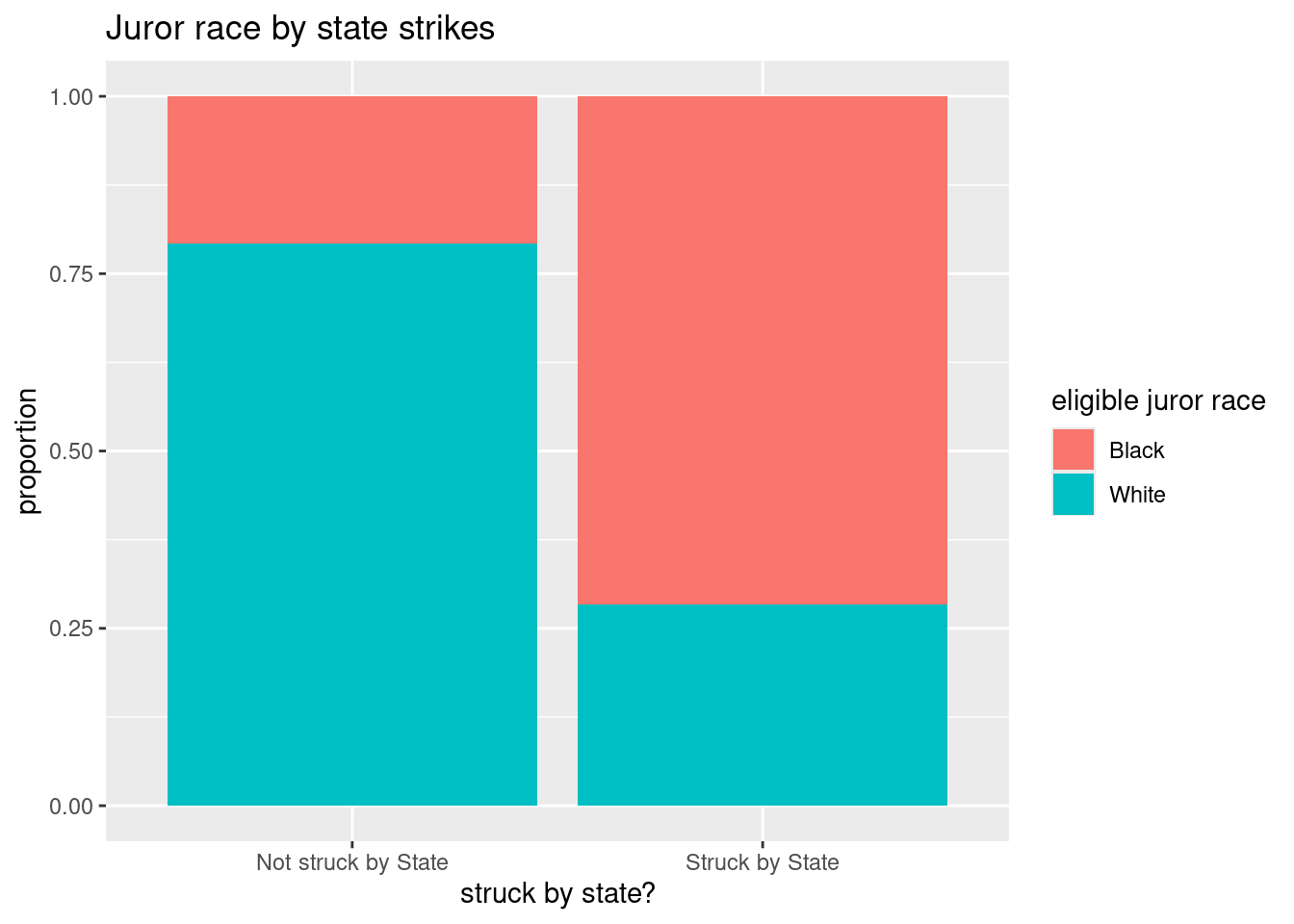
- What proportion of eligible jurors who were not struck by the state were black? were white?
Click for answer
Answer: Of all jurors not struck by the state, about 20.8% were black
Problem 2: Graduate programs acceptance and sex
How are grad school program acceptance rates associated with sex? We will look at a classic data set from Berkeley grad school applications from 1973 (Science, 1975). The data cases are applicants to four graduate programs at Berkeley during 1973. The variable result tells us if the applicant was accepted to the graduate program, sex tells us the sex of the applicant (male or female), and program tells us program type (programs 1,2,3 or 4).
grad <- read.csv("https://raw.githubusercontent.com/deepbas/statdatasets/main/BerkeleyGrad.csv")(a). Table of counts and proportions
prop.table(table(grad$result))
accept reject
0.4260119 0.5739881 - What proportion of applicants were accepted?
Click for answer
Answer: About 43% (1284/3014) of applicants were accepted.
(b). Two-way tables
The table command also gives two-way tables when two variables are included. Here is the two-way table for result and sex:
table(grad$sex, grad$result)
accept reject
female 262 587
male 1022 1143- How many applicants involved females who were accepted?
Click for answer
Answer: : 262 applicants involved females who were accepted.
(c). Conditional proportions: acceptance given sex
The prop.table command gives conditional proportions for a two-way table. First let’s save the two-way table in an object named mytable:
mytable <- table(grad$sex, grad$result)Then use prop.table to get the distribution of result conditioned (grouped) on applicant’s sex:
prop.table(mytable, 1)
accept reject
female 0.3085984 0.6914016
male 0.4720554 0.5279446The value of 1 in this command tell’s R that you want row proportions (the denominator of the proportion is each row total).
- What proportion of female were accepted?
Click for answer
Answer: about 31% (262/(262+587))
- What proportion of males were accepted?
Click for answer
Answer: about 47% (1022/(1022+1143))
(d). Bar graph for one variable
We can create a data frame count_data1 containing the counts and their corresponding categories.
counts1 <- table(grad$result)
count_data1 <- data.frame(counts1)Then, we use ggplot2 to create a bar plot with the categories on the x-axis and the counts on the y-axis. The column names of count_data are automatically assigned to be Var1 and Freq. We can change the column names to category and count, for example, as:
colnames(count_data1) = c("category", "count")
count_data1 category count
1 accept 1284
2 reject 1730The geom_bar(stat = "identity") function is used to create the bars, and we set the y-axis label using labs().
# Create a bar plot using ggplot2
library(ggplot2) # load the package
ggplot(count_data1, aes(x = category, y = count)) +
geom_bar(stat = "identity") +
labs(y = "count")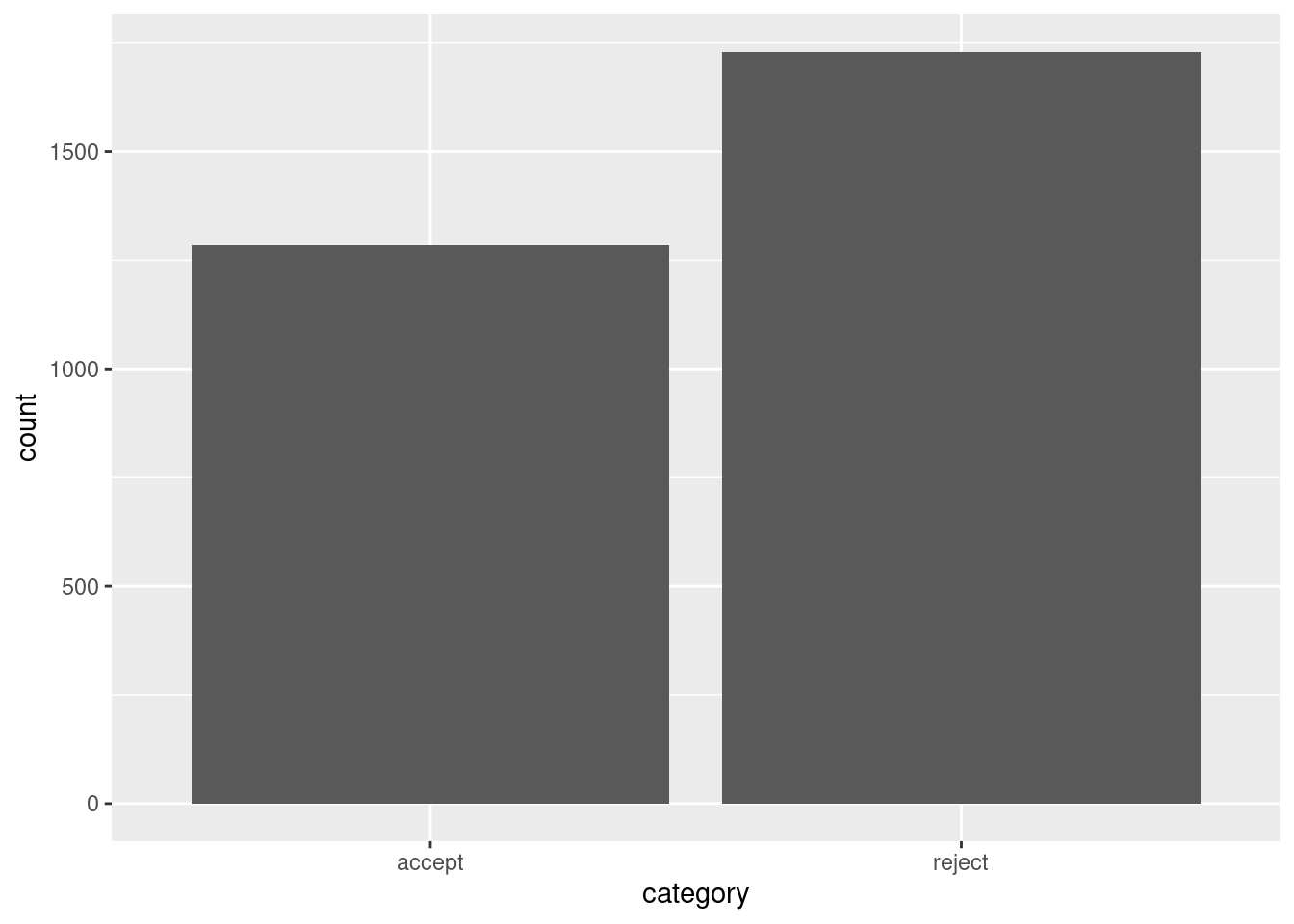
(e). Stacked bar graph for two variables
Now we can use the geom_bar command in this package. Here we get the conditional distribution of result given sex:
library(ggplot2) # don't need if you already entered it for example 1
ggplot(grad, aes(x = sex, fill = result)) +
geom_bar(position = "fill") +
labs(y="Proportion", title = "result by sex", fill = "result?", x = "sex")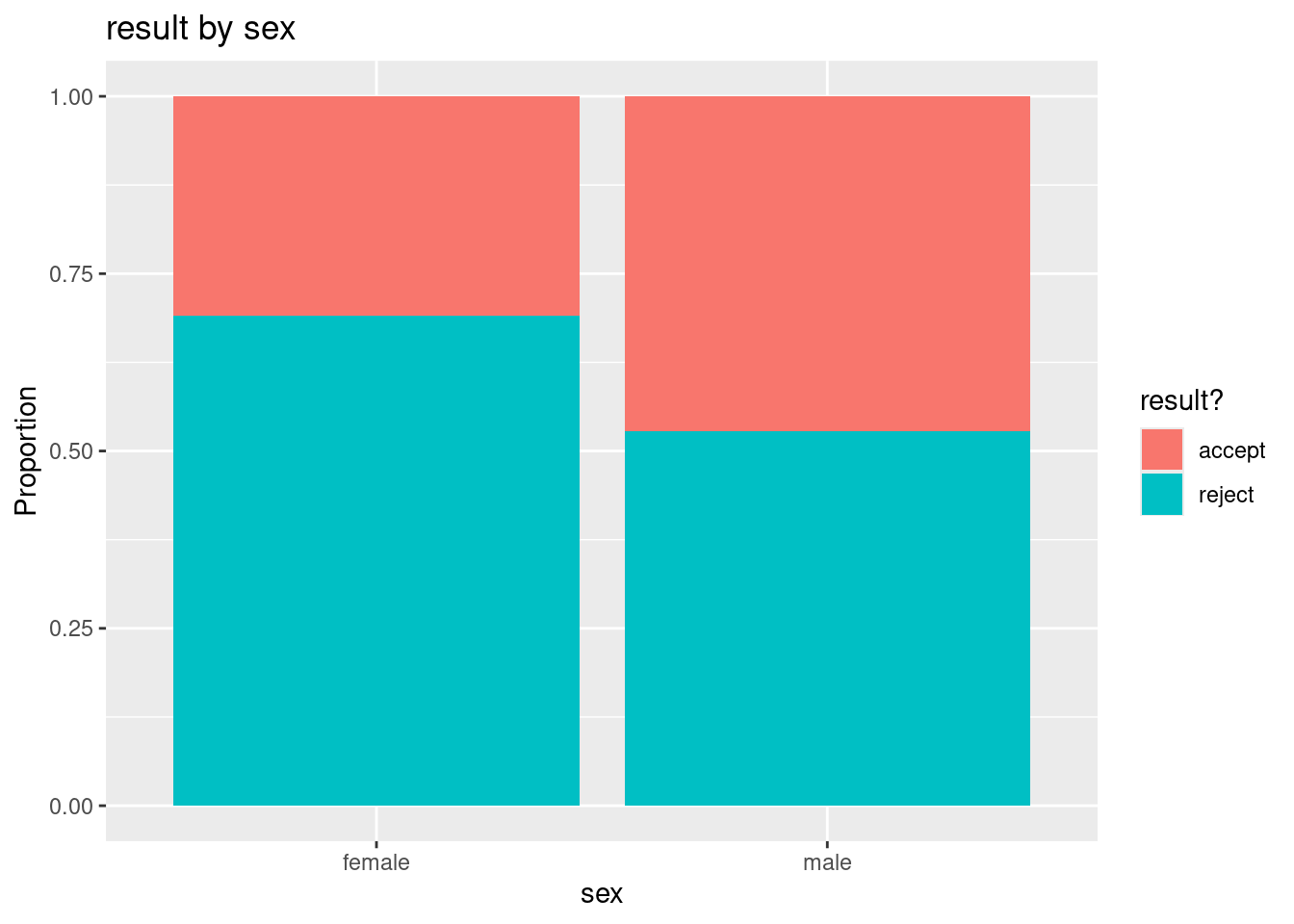
The basic syntax for this function is to let ggplot know your data set name (grad), then specify the grouping or conditional variable on the x-axis (sex) in the aes (aesthetic) argument. The fill variable is the response variable (result). We add (+) the geom_bar geometry to get a bar graph with the fill position specified. Adding an informative label and title complete the graph.
(f). Subsetting by program type
Finally, we will repeat the previous analysis of result and sex, but this time we will divide (or subset) the data set by program type. To do this we need to know how the values of program are coded:
table(grad$program)
program1 program2 program3 program4
933 585 782 714 Here we use the filter command available from the dplyr package to get only the applicants to program 1:
library(dplyr)
grad.p1 <- filter(grad, program == "program1") # gets rows where program equal program1
head(grad.p1) program sex result
1 program1 male accept
2 program1 male accept
3 program1 male accept
4 program1 male accept
5 program1 male accept
6 program1 male acceptdim(grad.p1)[1] 933 3- Repeat the
filtercommand to get a data set for program 2 and call the new data setgrad.p2. Verify that the number of rows in this dataset matches the number of program 2 applicants in the original data set.
# enter R code for (f) here
grad.p2 <- filter(grad, program == "program2") # gets rows where program equal program1
head(grad.p2) program sex result
1 program2 male accept
2 program2 male accept
3 program2 male accept
4 program2 male accept
5 program2 male accept
6 program2 male accept(g). Result by sex for program 1.
- The distribution of result conditioned on applicant’s sex for the program 1 data set is shown below.
ggplot(grad.p1, aes(x = sex, fill = result)) +
geom_bar(position = "fill") +
labs(y="Proportion", title = "result by sex for program 1",
fill = "result?", x = "sex")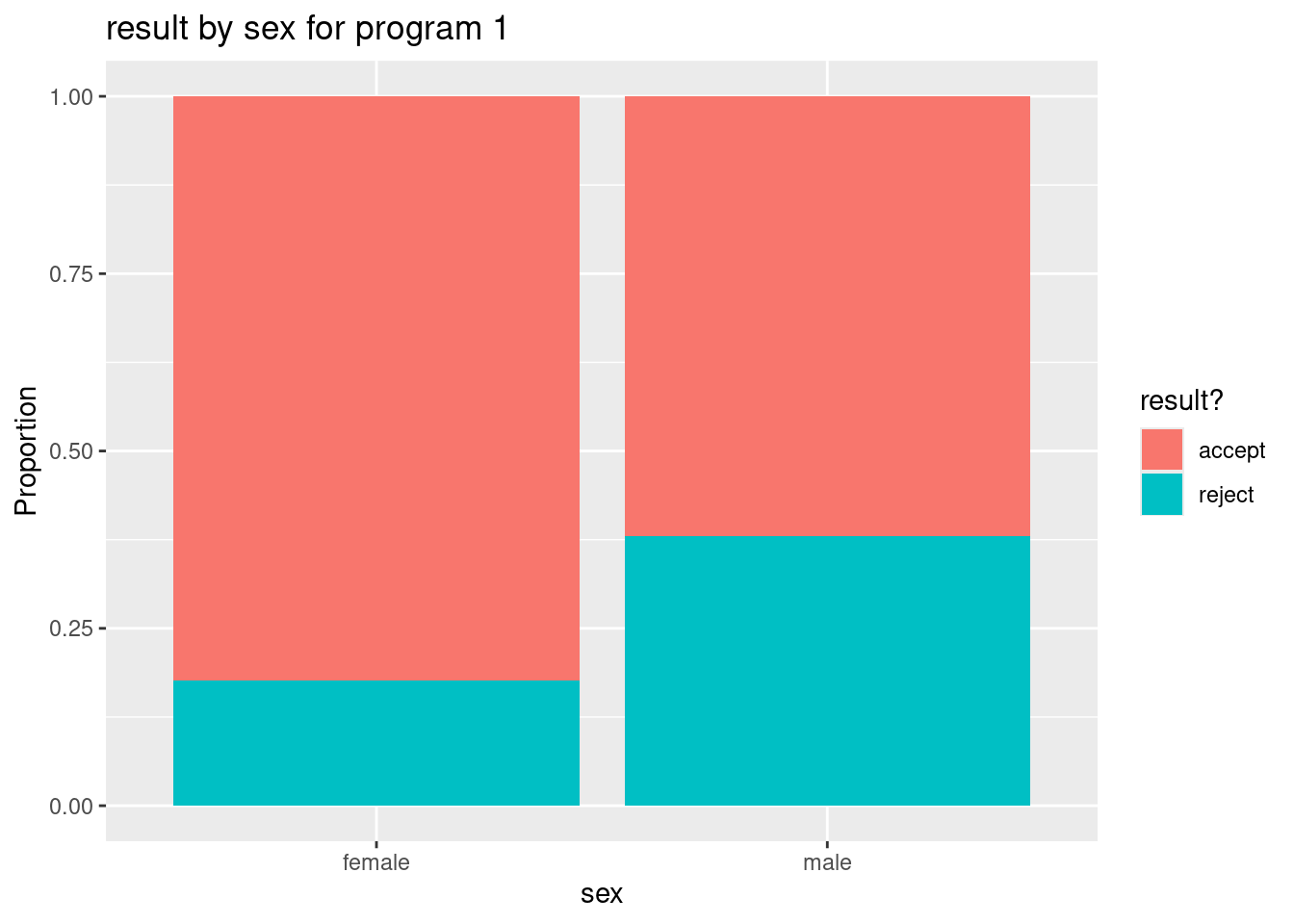
Get both a table of conditional proportions (or percentages) and a stacked bar graph.
Click for answer
prop.table(table(grad.p1$sex, grad.p1$result),1)
accept reject
female 0.8240741 0.1759259
male 0.6193939 0.3806061(h). Result by sex for program 2.
- Repeat part (g) but this time use the program 2 data set. Compare the two bar graphs for (g) and (h) and explain how they show that females have a higher acceptance rate after accounting for program type (1 or 2).
Click for answer
# enter R code for (h) here
ggplot(grad.p2, aes(x = sex, fill = result)) +
geom_bar(position = "fill") +
labs(y="Proportion", title = "result by sex for program 2",
fill = "result?", x = "sex")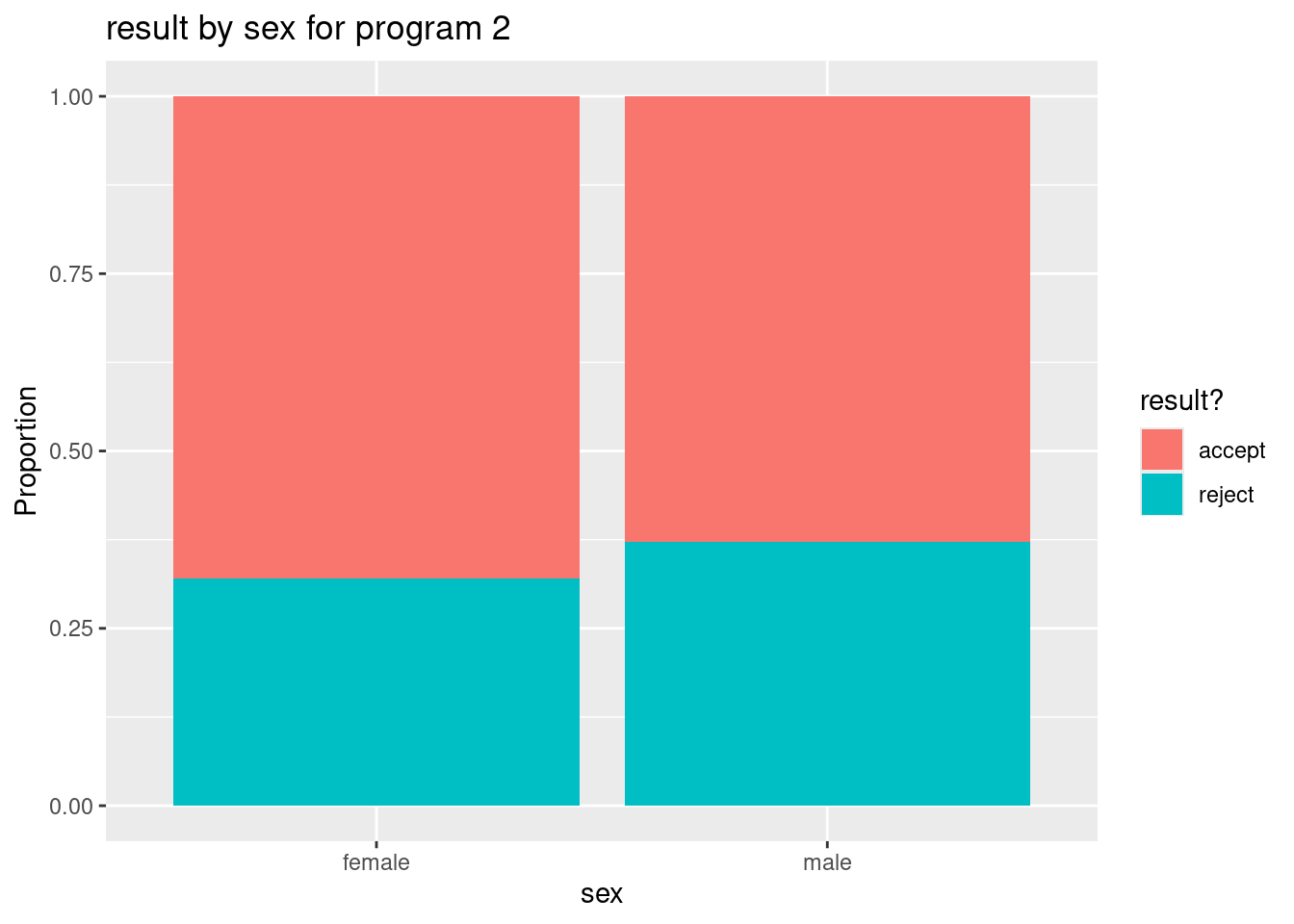
prop.table(table(grad.p2$sex, grad.p2$result),1)
accept reject
female 0.6800000 0.3200000
male 0.6285714 0.3714286Answer: For both programs 1 and 2, we see that female applicants have a slightly higher rate of acceptance than male applicants. After accounting for program type, we now see that female applicants have higher acceptance rate than male applicants. Without accounting for program type, the opposite was true (see parts (c) and (e)).
Why? the confounding affect of program type which is associated with both result and sex:
Click for answer
- females prefer to apply to programs 3 and 4 while males prefer programs 1 and 2 (more than 3 and 4).
- 44% of females applied to program 3 and 40% to program 4
- 38% of males applied to program 1 and 26% to program 2
prop.table(table(grad$sex, grad$program), 1)
program1 program2 program3 program4
female 0.12720848 0.02944641 0.44169611 0.40164900
male 0.38106236 0.25866051 0.18799076 0.17228637-Programs 3 and 4 were much harder to get into than programs 1 and 2 - 64% of applicants to program 1 were accepted and 63% of applicants to program 2 were accepted - 6% of applicants to program 4 were accepted and 34% of applicants to program 3 were accepted
prop.table(table(grad$program, grad$result), 1)
accept reject
program1 0.64308682 0.35691318
program2 0.63076923 0.36923077
program3 0.34398977 0.65601023
program4 0.06442577 0.93557423So since the majority of females applied to the toughest programs (as measured by acceptance rates), there overall rate of acceptance was lower for females compared to males. But when we break down these rates by program type, we see that females have higher acceptance rates than males (see the visual in part (i)).
(i). A bar graph with three variables
If we simply want to graph the relationship between result and sex for each type of program, we can avoid subsetting the data by using the facet_wrap command in ggplot2. It is one simple addition to the stacked bar graph in part (e):
ggplot(grad, aes(x = sex, fill = result)) +
geom_bar(position = "fill") +
labs(y="Proportion",
title = "result by sex for each program",
fill = "result?",
x = "sex") +
facet_wrap(~program)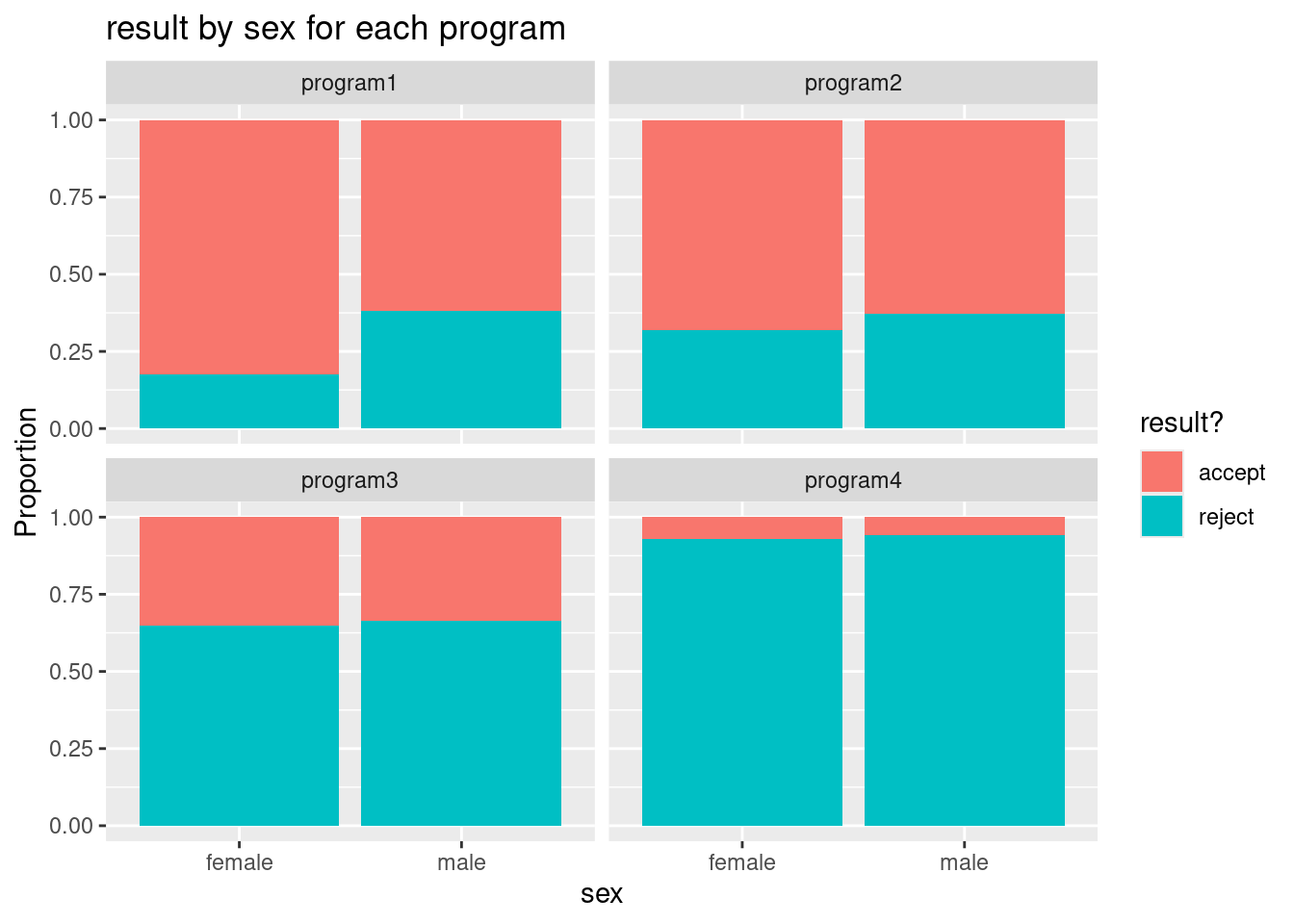
- Verify that this command creates side-by-side stacked bar graphs that match your graphs in parts (g) and (h) for programs 1 and 2.
Click for answer
Answer: The graphs match.